










Services on Demand
Journal

Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkLatin American applied research
Print version ISSN 0327-0793
Lat. Am. appl. res. vol.33 no.4 Bahía Blanca Oct./Dec. 2003
Robot control with inverse dynamics and non-linear gains
B. Morales and R. Carelli
Instituto de Automática, Facultad de Ingeniería. Universidad Nacional de San Juan
Av. San Martín Oeste 1109 - J5400ARL San Juan. Argentina.
{bmorales; rcarelli}@inaut.unsj.edu.ar
Abstract ¾ A motion control strategy for robot manipulators, with inverse dynamics and non-linear proportional-derivative gains is presented. On account of a possible interaction of the robot with the environment, impedance is incorporated to modify the robot's motion references according to the interaction force. The gains, that are non-linear state functions, allow to improve robot performance and to prevent actuator saturation. It is proved that an asymptotically stable closed-loop system is obtained with the proposed controller. Simulation results on a 3-dof robot show a good performance of the controller with variable gains, as opposed to that of a constant gain PD controller.
Keywords ¾ Robotics. Non-Linear Systems. Motion Control. Impedance Control.
I. INTRODUCTION
One of the basic problems in robot control is the so-called motion control, when a robot manipulator is required to follow a pre-established trajectory.
Current present-day manipulators use proportional-derivative controllers (PD) or proportional-integral-derivative controllers (PID) in closed-loop systems in order to reach the desired configurations. For an updated reference on PID controllers, see (Benett, 2001) and (Aström and Hägglund, 2001). It has been proven that PID controllers, despite their widespread use, do not show global asymptotic stability when controlling a robotic manipulator (Wen and Murphy, 1990). Various motion controllers with rigorous stability demonstrations can be found in the literature: (Sciavicco and Siciliano, 2000; Craig, 1989) among others.
The PD controller with gravity compensation produces a global asymptotically stable closed-loop system through a trivial selection of the proportional and derivative gains (Takegaki and Arimoto, 1981). The PD+ controller, introduced by Koditschek (Koditschek, 1984) is both simple and attractive. Its control structure is based on a linear PD feedback loop plus a specific compensation of robot dynamics. The first stability analysis of a PD+ controller was done by Paden and Panja (1988), who termed it PD+ control. Later, Whitcomb et al. (1993) present a rigorous stability analysis by introducing a Lyapunov function in an adaptive control context.
The global asymptotic stability analysis of a closed-loop system using the above-cited controllers has been carried out in the above mentioned papers by considering a selected set of constant gains of the controllers. This characteristic may constrain the application of these controllers when, in addition to asymptotic stability, a high performance of the control system is required as well. To have a good performance in manipulator control with actuator constrains implies to implement variable gains in the controllers. Variable-gain PD controllers for position and motion control of manipulators have been implemented in (Kelly and Carelli, 1996) and, recently, Santibañez et al. (2000) presented a variable-gain PD+ controller that uses fuzzy logic.
We present here an inverse dynamics controller with non-linear PD gains, which allows for motion and impedance control. It avoids saturation of control actions and improves the performance for small control errors.
The work is organised as follows. Section II describes the model and control scheme along with its stability analysis. The application of a control algorithm to a 3-dof manipulator is presented in Section III, and the conclusions in Section IV.
II. ROBOT MODEL AND CONTROLLER DESIGN
A. Robot Model
With no perturbations present, the joint-coordinates dynamic model of a robot manipulator interacting with the environment is:
 (1)
(1)
where t is the n ´ 1 vector of torques or forces applied on the joints,  is the manipulator's inertia matrix that is symmetric and positive definite;
is the manipulator's inertia matrix that is symmetric and positive definite;  is the matrix of centrifugal and Coriolis forces;
is the matrix of centrifugal and Coriolis forces;  is the vector of gravitational torques or forces;
is the vector of gravitational torques or forces;  is the friction force vector; fm is the vector of forces interacting with the environment and
is the friction force vector; fm is the vector of forces interacting with the environment and 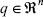 is the joints position vector.
is the joints position vector.
For an analysis of the interaction between manipulator and environment and, since this interaction is typically described in the operational space, it is convenient to refer the control schemes to such a space. Then, the dynamic model of the manipulator in Cartesian coordinates (Sciavicco and Siciliano, 2000) can be written as:
 (2)
(2)
where fa is the actuator force defined at the end effector, H* is the inertia matrix of the manipulator and 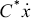 the centrifugal and Coriolis forces, Q is the friction force vector, g* the gravity force vector;
the centrifugal and Coriolis forces, Q is the friction force vector, g* the gravity force vector;  is the position vector in Cartesian coordinates and fm is the interaction force with the environment. This force, for an elastic environment, can be modelled by,
is the position vector in Cartesian coordinates and fm is the interaction force with the environment. This force, for an elastic environment, can be modelled by,
fm = Km (x - xe ) (3)
where Km is the environment's elasticity matrix and xe is the environment's position vector. The dynamic model of Eqn. (2) is defined outside the singular configurations of the robot.
B. Control Strategy
A simplified scheme for the proposed control is shown in Fig. 1.
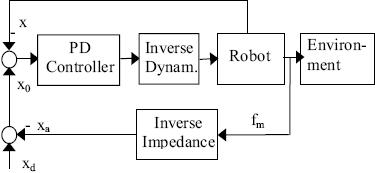
Figure 1. Control Scheme
The control law involves two feedback loops. One of them is external and generates a modified motion reference by adding a term obtained after filtering the interaction force by the inverse of the transfer function of the desired impedance (Carelli and Postigo, 1992). Besides, the modified reference is obtained for both the velocity and the acceleration. These modified references are applied to the internal loop.
The internal loop follows an inverse dynamics PD motion control law:
 (4)
(4)
where  is the error vector defined as:
is the error vector defined as: 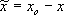 , and xo = xd xa, with xd the desired trajectory and the reference adjustment vector xa obtained by applying the impedance inverse to the interaction force, by means of the following law:
, and xo = xd xa, with xd the desired trajectory and the reference adjustment vector xa obtained by applying the impedance inverse to the interaction force, by means of the following law:
xa(t)[Ap2 + Bp + k]-1 fm(t) (5)
A, B, K are the matrices for the desired impedance, p=d/dt.
Note that if fm = 0, i.e., no contact with the environment is verified, then xo = xd, thus the manipulator follows the nominal reference.
The vector a in (4) is the resultant of a proportional-derivative controller with non-linear gains, defined by,
 (6)
(6)
where Kp, Kv are positive definite matrices given by:
 (7)
(7)
with
 | (8) |
and matrix Kv is given by
 , (9)
, (9)
with
 | (10) |
where kpi are constants to be determined in such a way that when  the controller will ensure that the robot follows the desired trajectory without saturating the actuators. The constants
the controller will ensure that the robot follows the desired trajectory without saturating the actuators. The constants  should be chosen in such a way that when
should be chosen in such a way that when  increases, the value of a remains bounded. Thus, the manipulator can follow the trajectory without going beyond the maximum values allowed for the actuators, provided the robot is moving within a region far enough from singularities. Then, to compute it is necessary to know the maximum acceleration amax attainable by the robot, or at least an estimation of this value from simulations. Then, knowing amax and applying limits to Eqn. (6) when
increases, the value of a remains bounded. Thus, the manipulator can follow the trajectory without going beyond the maximum values allowed for the actuators, provided the robot is moving within a region far enough from singularities. Then, to compute it is necessary to know the maximum acceleration amax attainable by the robot, or at least an estimation of this value from simulations. Then, knowing amax and applying limits to Eqn. (6) when  it follows that
it follows that
 (11)
(11)
where  depends on the followed trajectory. By solving the quadratic equation, the positive value of the root is chosen. After the above-mentioned definition of constants kpi, both Kp, Kv are positive definite matrices.
depends on the followed trajectory. By solving the quadratic equation, the positive value of the root is chosen. After the above-mentioned definition of constants kpi, both Kp, Kv are positive definite matrices.
Remark 1: in Eqns. (8) and (10), the tanh non linear function has been used, due to its good properties such as to be bounded between 1 and -1 with unity slope close to 0, continuous and odd. Note that any other function with similar properties could be also used in defining the variable controller gains.
A demonstration below will show that the proposed controller is asymptotically stable. The following lemma will be used
Lemma 1: If  is an increasing, odd, continuous function then
is an increasing, odd, continuous function then
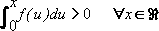 . (12)
. (12)
Proposition 1: Let the dynamic model of a robot be stated by Eqns. (4) and (6), where the elements of the gain matrices of the PD controller are defined by Eqns. (8) and (10). Then, the closed-loop system is asymptotically stable, and it is verified that
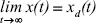 (13)
(13)
Proof: The closed-loop system obtained by combining the robot model (4) with the control law (6) can be expressed as
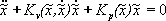 (14)
(14)
A Lyapunov candidate function is proposed as
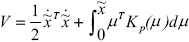 | (15) |
with a positive first term representing the norm of the velocity error vector. The second term can be expressed
 | (16) |
Each of the summation terms is
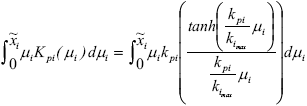 | (17) |
 | (18) |
and, bearing in mind that tanh is a continuous, odd and increasing function, by Lemma 1 it is verified that the integral (17) is positive. Then, function V is positive definite. As regards the time derivative  , it follows:
, it follows:
 (19)
(19)
Then, by substituting the closed-loop equation
 (20)
(20)
and, since by definition Kv is positive definite, we conclude that  is positive semi-definite. It should be resorted, then, to apply the Krasovski-Lasalle theorem (Vidyasagar, 1993). It can be verified that, within the set
is positive semi-definite. It should be resorted, then, to apply the Krasovski-Lasalle theorem (Vidyasagar, 1993). It can be verified that, within the set
 | (21) |
the origin is the unique invariant set. This can be verified by noting in the dynamic Eqn. (14) that, when  , the unique solution for
, the unique solution for  is
is  . Therefore, the origin of the space state is asymptotically stable, thus verifying Eqn. (13).
. Therefore, the origin of the space state is asymptotically stable, thus verifying Eqn. (13).
Remark 2: For the robot dynamics model as the one described in Eqn. (2), the analysis is valid outside the singular configurations of the robot, due to well known restrictions of inverse kinematics.
III. SIMULATION RESULTS
A model of PUMA 560 robot with 3-dof (waist, shoulder and elbow) (Troch and Desoyer, 1990) was used. Figure 2 shows a scheme of this robot.
The planned task is to polish a plane surface parallel to the x-y plane of the reference base system, following a trajectory defined by Santibañez et al. (2000):
 | (22) |

Figure 2. Robot scheme
with initial position at x0 = 0 ; y0 = 0.22m z0=0.56m.
The proposed inverse dynamics, non-linear gain PD controller was implemented, and the results obtained were contrasted with those of an inverse dynamics, constant gains PD controller. Gains for the second controller are listed in Table 1. For the variable gain controller, it was chosen kpi = 180 and amax = [1.5 10 10]. The value of was computed with Eqn. (11).
Table 1. Data of the Constant Gain Controller

The position errors obtained with both controllers are presented in Figs. 3 and 4. It can be noted that the constant-gain PD controller can not follow the trajectory with zero error. It oscillated about a constant error zone, because an increase in the gains saturates the actuators, as in Fig. 5. The variable-gain PD controller accomplished the trajectory without saturating the actuators, as shown in Fig. 6. Also, a good performance for the system is obtained. The reasons are that the gains decrease when the error is high, and they increase when the error tends to zero (see Fig. 7). Actuator saturation is thus avoided. The presence of non-modelled non-linear dynamics causes that the constant-gain proportional derivative controller does not reach the desired trajectory, whereas the proposed controller does attain the objective with a high performance, because it allows to increase the gains when the error is small without saturating the actuators. The non-modelled dynamics in this simulation corresponds to Coulomb's friction effects.

Figure 3: Position errors with variable gains

Figure 4: Position errors with constant gains

Figure 5: Voltages obtained with the constant-gain controller

Figure 6: Voltages obtained with the variable-gain controller

Figure 7: Variable Gains Kp of the controller
IV. CONCLUSIONS
This work has presented a control strategy for robot manipulators that allows to improve the performance and to avoid saturation of the control actions. The control is composed of an inverse-dynamics controller with PD gains that are non-linear state functions. It has been proven that the proposed controller is asymptotically stable. The simulation results show a good behaviour of the controller, which has reached the proposed objectives. It should be observed that, even though the work is referred to robot manipulators, the proposed controller can be applied to any second order non-linear system which allows for feedback linearization.
ACKNOWLEDGEMENTS
The authors acknowledge CONICET, ANPCyT and UNSJ for partially funding the work. Also, B. Morales acknowledges the Department of Mathematics, School of Engineering, where she holds a professor position, for their institutional support during her work at Instituto de Automática in pursuing the Master's Degree in Control Systems Engineering.
REFERENCES
1. Aström K. J.and T. Hägglund. "The future of PID control", Control Engineering Practice, 9, 1163-1175 (2001). [ Links ]
2. Bennett S. "The past of PID controllers", Annual Reviews in Control, 25, 43-53 (2001). [ Links ]
3. Carelli R. and J. Postigo. "Adaptive Impedance Controller for Robot Manipulators", Journal of Engineering I.R. of Iran, 3 (3&4) 76-83 (1992). [ Links ]
4. Craig, J. Introduction to Robotics. Addison Wesley (1989). [ Links ]
5. Kelly R. and R. Carelli. "A class of nonlinear PD-type controllers for robot manipulators", Journal of Robotic System, 13 (12):793-802 (1996). [ Links ]
6. Koditschek, D., "Natural motion for robots arms", Proceedings of the 1994 IEEE Conference on Decision and Control 733-738 (1994). [ Links ]
7. Padem, B. and R. Panja. "Globally asymptotically stable PD+ controller for robot manipulators" . Int. J. Control, 47(6):1697-1712 (1988). [ Links ]
8. Santibañez, V., R. Kelly and M. Llama. "Fuzzy PD+ control for robot manipulators". Proceedings of the 2000 IEEE International Conference on Robotic and Automation, 2112-2117 (2000). [ Links ]
9. Sciavicco, L. and B. Siciliano. Modelling and Control of Robot Manipulators, Springer, (2000). [ Links ]
10. Takegaki, M. and S. Arimoto. "A new feedback method for dynamic control of manipulators", J. Dyn. Sys. Meas. Control Transaction. ASME ,103 119-125 (1981). [ Links ]
11. Troch, K. and K. Desoyer. "Benchmark Problems for Control System Design", Report of the IFAC. Theory Committee. Edited by E.J. Davison, 45-49 (1990). [ Links ]
12. Vidyasagar, M. Nonlinear Systems Analysis. Prentice-Hall Int., (1993). [ Links ]
13. Wen, J. T. and S. Murphy. "PID control for robot manipulators", Rensselaer Polytechnic Institute, CIRSSE, (1990). [ Links ]
14. Whitcomb, L., A. Rizzi and D. Koditschek. "Comparative experiments with a new adaptive controller for robot arms", IEEE Transactions on Robotic and Automation 9(1), 59-70 (1993). [ Links ]

