










Servicios Personalizados
Revista

Articulo
 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkLatin American applied research
versión impresa ISSN 0327-0793versión On-line ISSN 1851-8796
Lat. Am. appl. res. vol.43 no.3 Bahía Blanca jul. 2013
Classification of asr word hypotheses using prosodic information and resampling of training data
E.M. Albornoz†, D.H. Milone†, H.L. Rufiner† and R. López-Cózar‡
† Centro de Investigación en Señales, Sistemas e Inteligencia Computacional (SINC(i)), Facultad de Ingeniería y Ciencias Hídricas, Universidad Nacional del Litoral, Santa Fé, Argentina. Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET) emalbornoz@fich.unl.edu.ar d.milone@ieee.org lrufiner@fich.unl.edu.ar
‡ ETSI Informática y de Telecomunicación, Universidad de Granada, Granada, España. rlopezc@ugr.es
Abstract — In this work, we propose a novel resampling method based on word lattice information and we use prosodic cues with support vector machines for classification. The idea is to consider word recognition as a two-class classification problem, which considers the word hypotheses in the lattice of a standard recognizer either as True or False employing prosodic information. The technique developed in this paper was applied to set of words extracted from a continuous speech database. Our experimental results show that the method allows obtaining average word hypotheses recognition rate of 82%.
Keywords — Automatic Speech Recognition; Resampling Corpus; Support Vector Machines; Hypotheses Classification.
I. INTRODUCTION
Over the last years, prosodic information has become a very interesting line of research. A lot of efforts have been made to model and incorporate it in Automatic Speech Recognition (ASR) systems. In doing so, two important issues must be considered. On the one hand, extracting and modeling the prosodic elements to be employed, whilst on the other, finding the best way to incorporate them in an ASR system. A number of papers can be found in the literature addressing these issues.
For example, Milone and Rubio (2003) proposed to use a combination of prosodic features and accentuation to model Spanish words. A prosodic binary classifier for syllable stress that is used with ToBI (Tones and Break Indices) (Silverman et al., 1992) information to evaluate the ASR hypotheses is defined by Ananthakrishnan and Narayanan (2007). Szaszák and Vicsi (2007) used prosodic information to train a small set of Hidden Markov Models (HMM) in order to segment prosodic units in Hungarian language. Huang and Renals (2008) proposed a method where prosodic features in syllables are categorized in 16 classes using vector quantization, and words are defined as a concatenation of these classes. In another work (Vicsi and Szaszák, 2010) the supra-segmental features of speech are modeled with prosody in a traditional HMM framework. This method is designed for fixed-stress languages where a segmentation for syntactically linked word groups is done. Albornoz and Milone (2005) proposed a prosodic model for Spanish word classification. It uses the orthographic rules of Spanish to do groups of words depending on the separation of the syllables. In every word, prosodic information is compared among syllables in order to obtain a code of the relative magnitude measured in each one.
However, some problems arise with the ASR system when prosodic analysis is in the level of syllables. For example, confusions do not only appear among words with the same number of syllables, and for this reason the information from orthographic rules is not so useful. Another problem is that the recognizer usually makes mistakes for some particular words. Using word nets, an additional problem is that nets do not always have the true hypothesis in every speech segment.
In this paper, we present a method to address errors of the acoustic models typically employed in a standard HMM-based speech recognizer. We propose to develop word classifiers to identify the incorrect hypotheses in problematic speech segments. Moreover, we propose an original alternative to tackle the problem of choosing the proper data to train these classifiers. On the other hand, the incorporation of this information in an ASR system will be considered in future works.
The remainder of the paper is organized as follows: in Section 2 the proposed method is presented, where it is explained a new resampling methodology for a speech corpus and how to use it in order to classify word hypotheses; Section 3 introduces the features extraction process and discusses an experiment that, for each word, explores different configurations, features vectors and classifiers; then, the Section 3 presents a second experiment which uses the best configurations and test data; finally, Section 4 presents conclusions and discusses possibilities for future work.
II. THE PROPOSED METHOD
Usually, the first step in a simple word classifier is to extract acoustic segments and label them according to the corresponding word in the utterance. From these segments, different features are computed and selected to compose the inputs for the classifier. In this way, after the training phase, the classifier would be able to predict one word from a set of features that it has never seen before.
State-of-the-art HMM-based ASR systems (Rabiner and Juang, 1993) may have good performance in appropriate conditions, but sometimes have problems with particular words, for example, due to the accents of the speakers. Thus, the focus of our method is the re-analysis of these problematic segments.
The proposed methodology is based on the analysis of the recognition hypothesis space provided by an ASR system when it recognizes an utterance. It requires creating an HMM-based ASR system in the standard way and generates N-Best word lattices for all training utterances. These lattices are used to build a lattice corpus by resampling, which is used to train word classifiers with additional features. The resampling process for the classifier is explained in the next sections.
A. N-best hypotheses resampling
The speech signals used in the experiments were taken from the Albayzin corpus, a Spanish continuous speech database, developed by five Spanish universities (Moreno et al., 1993). In the experiments, we have used 4400 utterances corresponding to the training set in the corpus. The corpus utterances were spoken by 88 people, 44 females and 44 males, and its length is about 259 minutes.
In order to create a standard HMM-based ASR system, we used the Hidden Markov Model Toolkit (HTK) (Young et al., 2001). The classic Mel-frequency cepstral coefficients (MFCC) parameterization was calculated using a Hamming windows of 25 ms with a 10 ms frame shift. The first 12 MFCCs and the energy plus their first and second derivatives were extracted. Acoustic models for phone-based recognition and a bigram language model were generated.
Then, we created an N-best list of hypotheses (N=10) for every training utterance. Acoustic segments were extracted from the utterances using the information about the Viterbi alignments (forced alignment) of word hypotheses. For each word in the utterance, the word hypotheses were inserted either in a set called True or in a set called False, depending on the correspondence between the hypotheses and the orthographic transcription of the utterance. For example, Figure 1 shows a word lattice for a speech segment where some hypotheses match with the transcription. In this example, there are three True hypotheses for the word dime, one False hypothesis for the word casa and one False hypothesis for the word grande.

Figure 1: N-best instance for a speech segment.
We have defined two rules in order to balance the sets of True and False hypotheses obtained.
- All the repeated True hypotheses are discarded to avoid redundancy.
- All False hypotheses are kept because little redundancy is found in this set.
The second rule allows considering more varied True hypotheses. The data in the two sets is resampled to balance the size of the sets. To do so, we consider the following rules:
- If count(True)>count(False) ⇒ the True set is defined by simple random sampling without replacement of True data.
- If count(True)<count(False) ⇒ False set is defined as the unreplicated False data plus simple random sampling without replacement of these data.
B. Feature extraction and classification models
As discussed in Section I, prosodic features such as F0 and energy have been extensively used for ASR (Ananthakrishnan and Narayanan, 2007; Huang and Renals, 2008; Szaszák and Vicsi, 2007). Many prosodic parameters can be extracted from these features, for example, mean, minimum, maximum and slopes. In the next section, the chosen parameters are explained.
As our method requires a binary classifier and one of the two sets of hypotheses is very populated, we have used support vector machines (SVMs). A SVM is a supervised learning method widely used for pattern classification, which has theoretically good generalization capabilities. Its aim is to find a hyperplane able to separate input patterns in a sufficiently high dimensional space (Bishop, 2006). In the experiments we have used the LIBSVM library (Chang and Lin, 2011) to process the patterns obtained from the prosodic parameters. The proposed method implements a one-against-all classification scheme where one represents the true hypotheses (given that there are many and diverse false hypotheses). Therefore, the classifier should fit the frontier region for the True class and the remaining space should be for the False class. Following this approach, the classifier can deal with word hypotheses not observed in the training, which may correspond to out-of-vocabulary words.
III. EXPERIMENTS
We first discuss how we have chosen the feature vectors and the best SVM model for each word. Then, we report on the tests that we have carried out using these models, with data partitions not observed in the training.
In this work, twelve of the most confused words were selected according to the ASR errors. These were computed in the N-Best extraction stage. For every word, a training/ test partition with the balanced corpus was generated. 80% of the data was randomly selected for training and the remaining 20% was left for test. The experiments were performed using raw data on one
Table 1: Best classification results (in %) for different sets of raw features using training data.
Table 2: Best classification results (in %) for different sets of normalized features using training data.
hand, and normalized data on the other, in order to compare the relevance of the normalization step. Each feature dimension was independently normalized in the training stage, using its maximum and minimum. Then, these scale factors were used in the test stage.
We used the Praattoolbox (Boersma and Weenink, 2010) to extract F0, Energy, F1 , Bandwidth of F1, F2 and Bandwidth of F2 from the recognition hypotheses. Their minimum, mean, maximum, standard deviation, skewness and kurtosis coefficients were also computed to create features vectors (FV) that have 42 features: the mentioned 36 features plus minimum and maximum distance between F1 and F2, square of the euclidean distance between F1 and F2, and F0, F1 and F2 slopes.
For each word, the F-Score measure was used to rate the features depending on their discriminative capacity (Chen and Lin, 2006). Given the feature vectors FVk this score was computed considering the True instances (NT) and the False instances (NF) as follows:

where 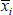 is the average of the ith feature,
is the average of the ith feature, 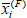 and
and 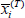 are the average False and True instances respectively, and xj,i is the ith feature in the jth instance.
are the average False and True instances respectively, and xj,i is the ith feature in the jth instance.
In a first experiment, using the rated features we created 12 different input patterns for each word, considering the 2, 4, 6, 8, 10, 12, 14, 16, 21, 26 and 32 most discriminative features on one hand, and all the features (42) on the other. For each feature set, SVM parameters were explored in order to create the best classification model. Every SVM model used a radial basis function kernel, the accuracy of which was computed using a five-fold cross validation scheme, considering the training data only. As a result we obtained the classification accuracy and the best parameters for each feature set. The selected features for each set are not usually the same for different words. Tables 1 and 2 show the classification accuracy for raw and normalized training data using the best parameters found. In these tables, the number of features for each set is showed in the first row.
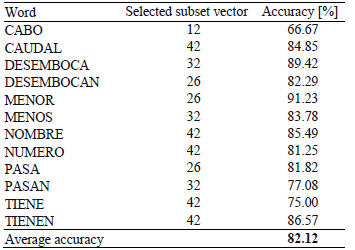
In a second experiment, a new SVM model was trained with the whole training data for each word, using the settings that achieved the best accuracy in the first experiment. All SVM models were tested with the aforementioned test partitions. Tables 3 and 4 set out the results obtained. It can be observed that these models achieved good results classifying word hypotheses. The average recognition rate improved when normalization was applied, but this process required more features. It should be noted, however, that the normalization process is not very useful for all words, as can be observed in the tables. For example, the classification rate for the word MENOR was 77.19% using raw features and 91.23% using normalized features, whereas for the word NOMBRE it was 90.20% using raw features and 85.49% using normalized features. This suggests that the normalization process could be customized for each word in order to improve the performance.
Table 3: Word hypotheses classification results for test raw data.
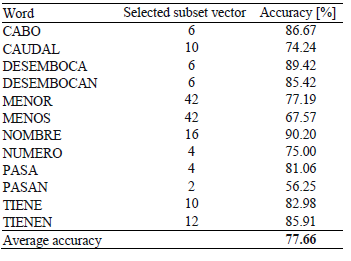
Table 4: Word hypotheses classification results for test normalized data.
IV. CONCLUSIONS AND FUTURE WORK
In this work, we have presented an approach aimed to improve the performance of standard ASR systems, which considers word lattices and prosodic cues. In accordance with this method, firstly, word lattices generated by a standard HMM-based speech recognizer are used to extract word hypotheses. Secondly, these hypotheses are the input to single-word classifiers that distinguish between True and False hypotheses considering prosodic information. The experimental results show that the method achieves average word accuracy of 82% when applied to a speech database in Spanish. Although more experimentation is needed, these results are promising in order to get an improvement in the performance of a standard ASR system. Moreover, the method could be applied to any language as it is language-independent because the method does not include any specific Spanish rule.
In future work we will integrate the method in a standard ASR system to increase the probabilities of the true hypotheses in the recognition network. Classifying word hypotheses using prosodic features would allow to process a real ASR problem efficiently. Results indicate that every word should be dealt with a specific model configuration in order to improve the recognizer performance. In addition, we plan to work on an "one-pass" system that, using our method, will take as input the alignments of the hypotheses and will produce the ASR result.
ACKNOWLEDGEMENTS
The authors wish to thank: Agencia Nacional de Promoción Científica y Tecnológica and Universidad Nacional de Litoral (with PAE 37122, PAE-PICT00052, CAID IIR4-N14) Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET) from Argentina, Universidad de Granada from España, Programa Erasmus Mundus External Cooperation Window - Lote 16 EADIC for their support.
REFERENCES
1. Albornoz, E.M. and D.H. Milone, "Construcción de patrones prosódicos para el reconocimiento automático del habla," 34th JAIIO, Rosario, Argentina, 225-236 (2005). [ Links ]
2. Ananthakrishnan, S. and S. Narayanan, "Improved Speech Recognition using Acoustic and Lexical Correlates of Pitch Accent in a N-Best Rescoring Framework," IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 4, 873-876 (2007). [ Links ]
3. Bishop, C.M., Pattern Recognition and Machine Learning, 1 ed., Springer (2006). [ Links ]
4. Boersma, P. and D. Weenink, PRAAT: doing phonetics by computer, Version 5.1.32 (2010). [ Links ]
5. Chang, C.-C. and C.-J. Lin, "LIBSVM: A library for support vector machines," ACM Transactions on Intelligent Systems and Technology, 2, 1-27 (2011). [ Links ]
6. Chen, Y.-W. and C.-J. Lin, "Combining SVMs with Various Feature Selection Strategies," Feature Extraction, Series: Studies in Fuzziness and Soft Computing, Springer Berlin Heidelberg, 207, 315-324 (2006). [ Links ]
7. Huang, S. and S. Renals, "Using Prosodic Features in Language Models for Meetings," Machine Learning for Multimodal Interaction of LNCS, Springer Berlin, 4892, 192-203(2008). [ Links ]
8. Milone, D.H. and A.J. Rubio, "Prosodic and accentual information for automatic speech recognition," IEEE Trans. on Speech and Audio Processing, 11, 321-333 (2003). [ Links ]
9. Moreno, A., D. Poch, A. Bonafonte, E. Lleida, J. Llisterri, J.B. Marino and C. Nadeu, "Albayzin speech data base: design of the phonetic corpus," 2nd European Conf. of Speech Communication and Technology, Berlin, 175-178 (1993). [ Links ]
10. Rabiner, L. and B.-H. Juang, Fundamentals of Speech Recognition, Prentice-Hall Inc., Upper Saddle River, NJ, USA (1993). [ Links ]
11. Silverman, K., M. Beckman, J. Pitrelli, M. Ostendorf, C. Wightman, P. Price, J. Pierrehumbert and J. Hirschberg, "TOBI: a standard for labeling English prosody," 2nd Int. Conf. on Spoken Language Processing, Banff, Alberta, Canada, 867-870 (1992). [ Links ]
12. Szaszák, G. and K. Vicsi, K., "Using Prosody in Fixed Stress Languages for Improvement of Speech Recognition," Verbal and Nonverbal Communication Behaviours of LNCS, Springer Berlin, 4775, 138-149 (2007). [ Links ]
13. Vicsi, K. and G. Szaszák, "Using prosody to improve automatic speech recognition," Speech Communication, 52, 413-426 (2010). [ Links ]
14. Young, S., G. Evermann, D. Kershaw, G. Moore, J. Odell, D. Ollason, V. Valtchev and P. Woodland, The HTK Book (for HTK Version 3.1), Cambridge University Engineering Department, England (2001). [ Links ]
Received: April 12, 2012
Accepted: October 15, 2012
Recommended by Subject Editor: Gastón Schlotthauer, María Eugenia Torres and José Luis Figueroa.

