










Services on Demand
Journal

Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO  uBio
uBio
Share

 Permalink
PermalinkEcología austral
On-line version ISSN 1667-782X
Ecol. austral vol.15 no.2 Córdoba July/Dec. 2005
TRABAJOS ORIGINALES
En busca de la independencia perdida: la utilización de Modelos Lineales Generalizados Mixtos en pruebas de preferencia
Arnaldo Mangeaud 1, 2,* & Martín Videla 1
1. Centro de Investigaciones Entomológicas de Córdoba, Facultad de Ciencias Exactas Físicas y Naturales, Universidad Nacional de Córdoba, Córdoba, Argentina
2. Cátedra de Estadística y Biometría, Facultad de Ciencias Exactas Físicas y Naturales, Universidad Nacional de Córdoba, Córdoba, Argentina
*Centro de Investigaciones Entomológicas de Córdoba. Facultad de Ciencias Exactas Físicas y Naturales, Universidad Nacional de Córdoba. Av. Vélez Sarsfield 299, X5000JJC, Córdoba, Argentina. Email: amangeaud@com.uncor.edu
Recibido: 9 de junio de 2004;
Fin de arbitraje: 20 de agosto de 2004;
Revisión recibida: 22 de abril de 2005;
Aceptado: 10 de agosto de 2005.
RESUMEN. La preferencia de organismos por ciertos recursos es frecuentemente evaluada mediante pruebas de elección múltiple, sin tener en cuenta en los análisis la dependencia entre las observaciones. Este trabajo presenta distintos modelos estadísticos que permiten contemplar la falta de independencia de los datos y compara la ´performance´ de cada uno de ellos empleando datos reales no simulados. Se utilizaron cuatro tipos de modelos: Análisis de Devianza (Modelo Lineal Generalizado Mixto), Análisis de la Varianza a un factor, ANOVA a un factor con bloque al azar (ambos Modelos Lineales Generales Mixtos), y ANOVA no paramétrico con bloques (Test de Friedman). También se utilizaron una covariable y una variable compensadora (´offset´). Los resultados obtenidos sugieren que para la variable de tipo conteo (con distribución Poisson), el Modelo Lineal Generalizado Mixto fue el más potente, mientras que si se considera la medida relativizada (conteos/superficie), la mayor potencia la obtuvo el MLG con una variable compensadora.
Palabras clave: Pruebas de elección múltiple; Preferencia alimentaria; Modelos estadísticos; Devianza.
ABSTRACT. Looking for the lost independence: using Mixed Generalized Linear Models in choice tests: The preference of organisms for resources is usually evaluated through multiple-choice tests, without accounting the lack of independence present in the data. This study presents several statistical models which explicitly consider such dependence structure comparing their performance by using real non-simulated data. Four types of models were used: Analysis of Deviance (Generalized Mixed Linear Model), Analysis of Variance with a factor, One-way ANOVA with random block effect (both General Mixed Linear Models) and Non-Parametric ANOVA with block effect (Friedman Test). A covariable and an offset variable were also added to the Mixed GLM model. Results suggest that the most powerful model for the counting-type variable (with Poisson distribution), is the Mixed GLM; whereas for the relativized variable (count/surface), is the Mixed GLM with an offset variable.
Keywords: Multiple choice test; Feeding preference; Statistical models; Deviance.
INTRODUCCIÓN
La utilización selectiva de los recursos por parte de los organismos puede tener importantes consecuencias ecológicas y evolutivas, razón por la cual ha sido intensamente estudiada en diferentes sistemas (Karban & English-Loeb 1997; Poore & Steinberg 1999). Esta preferencia es frecuentemente evaluada mediante experimentos de elección múltiple (multiple choice tests), en los cuales las distintas opciones son presentadas a los individuos en forma simultánea dentro de una jaula o caja. Luego de un período de tiempo, se miden las distintas variables de preferencia en cada tratamiento. Este tipo de experimento ha sido criticado en relación a dos aspectos que plantean ciertas dificultades en el diseño y análisis de los resultados. El primero, si bien no se da en todos los casos, es la necesidad de tener en cuenta los cambios autogénicos (crecimiento, reproducción, etc.) que ocurren en las unidades experimentales (ver Peterson & Renaud 1989; Roa 1992; Manly 1993). El segundo, es la dependencia entre las observaciones, ya que la actividad desarrollada por los individuos (consumo, oviposición, etc.) en una de las opciones, no es independiente de la actividad realizada en las restantes. Esto último, ha llevado a numerosos autores a utilizar pruebas estadísticas inadecuadas o poco potentes en el análisis de los resultados de las pruebas de preferencia de elección múltiple. En algunos trabajos, se contabiliza el número total de eventos ocurridos (punciones, oviposturas, etc.) y se realizan pruebas Chi cuadrado de uniformidad en la distribución para probar si el número de éstos es significativamente diferente entre los tratamientos (Mc Millin & Wagner 1998). Sin embargo esto no es lo correcto, ya que en el experimento la unidad de observación es el habitáculo, y en el análisis es el evento.
En los casos en que existen solo dos posibilidades de elección, los datos son analizados con las clásicas pruebas apareadas: test ´t´ apareado o test de los rangos con signos de Wilcoxon (Mayhew 1998; Steinbauer et al. 1998). Si bien estas pruebas contemplan la dependencia de los datos, requieren un gran esfuerzo cuando la cantidad de tratamientos aumenta debido a que las comparaciones deben hacerse de a pares. A su vez, debe utilizarse la protección de Bonferroni para extraer conclusiones globales, lo que implica disminuir los valores de alfa inicial (a= 0.05, error de tipo I a a = 0.05/ número de comparaciones).
En algunos trabajos, los datos se analizan mediante Análisis de la Varianza clásico (ANOVA) ignorando por completo el supuesto de independencia (e.g. Stuart & Polavarapu 1998). Este modelo, perteneciente al grupo del los Modelos Lineales Generales (ML)(Graybill 1976), se expresa de la siguiente manera:
![]()
donde: yij es el valor de la variable respuesta, µ es la media poblacional, ai es el efecto del iésimo tratamiento y εij es el error aleatorio. Este modelo supone que los errores son normales, con homogeneidad de varianzas e independientes entre sí, es decir:
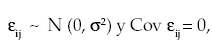 | para toda | |
En muchos casos, la variable en estudio no posee distribución normal. Si esto ocurre, no se cumplen los supuestos para los errores y las sugerencias apuntan a transformar la variable para forzar el cumplimiento de dichos supuestos, estabilizando varianzas y normalizando distribuciones (Kuehl 2001). Otra alternativa es utilizar modelos más potentes y adecuados como los Modelos Lineales Generalizados (MLG), los cuales permiten trabajar con variables cuya distribución forme parte de la familia exponencial (e.g., Poisson, Binomial, etc.). En estos análisis, la medida de variabilidad utilizada que cumple con la propiedad de poseer máxima verosimilitud, es la denominada Devianza (McCullagh & Nelder 1989). Cuando la distribución es normal, la Varianza es la medida que, además de la propiedad de los mínimos cuadrados, posee máxima verosimilitud ya que el ANOVA y los ML en general son un caso particular de los MLG. Estos últimos se definen como:
![]()
donde: ηi se denomina predictor lineal, µ es la media poblacional y αi es el efecto del iésimo tratamiento. El predictor lineal se construye de diferente forma según cuál sea la distribución de la variable en estudio. En la distribución Poisson la función de enlace (relación entre el predictor lineal y la media de cada tratamiento) es:
![]()
Los modelos descriptos anteriormente solo permiten el análisis de efectos fijos. La incorporación de uno o más factores con efectos aleatorios transforma a estos modelos en ML Mixtos (Piepho & Ogutu 2002) y MLG Mixtos (Littel et al. 1996), los cuales se definen mediante las siguientes ecuaciones:
| | y | |
donde δj representa un efecto aleatorio.
Otra forma de contemplar la dependencia, es modelar directamente la matriz de varianzascovarianzas. La independencia entre las unidades de observación implica que la covarianza o correlación entre ellas deba ser cero. Presuponer esto es erróneo, sobre todo si las características del diseño del experimento indican que es posible que haya dependencia entre los datos. Trabajar con una matriz que contemple la correlación entre los datos dependientes y no la suponga cero, permite desligarse del supuesto de independencia. Por otra parte, en los MLG, la homogeneidad de varianzas no es un supuesto ya que éstas pueden ser estimadas para cada uno de los tratamientos (Littel et al. 1996).
La utilización de modelos estadísticos inadecuados en el análisis de pruebas de libre elección está muy difundida en la literatura. El problema se debe, en parte, a la dificultad que plantea a biólogos, ecólogos y demás profesionales, la utilización de modelos estadísticos complejos (e.g., MLG Mixtos) que requieren conocimientos más profundos de estadística. En este trabajo se pretende acercar posiciones entre biólogos y estadísticos mediante un lenguaje accesible para ambos. Se evalúa el comportamiento de distintos modelos que consideran explícitamente la falta de independencia entre las observaciones en pruebas de preferencia utilizando datos reales no simulados.
MÉTODOS
Se realizaron pruebas de libre elección para evaluar la preferencia alimentaria de Liriomyza huidobrensis (Diptera: Agromyzidae) (Spencer 1973), una mosca minadora de hojas polifitófaga de importancia económica (Weintraub & Horowitz 1995). Se colocaron 10 hembras durante 3 horas en jaulas entomológicas de 2700 cm³ junto a tres plantas hospedadoras de especies vegetales diferentes: Vicia faba L., Phaseolus vulgaris L. y Cucurbita maxima var. zapallito Duch. (haba, poroto y zapallito respectivamente), las cuales fueron cultivadas en laboratorio. Las distintas réplicas (10) fueron realizadas simultáneamente con grupos diferentes de hembras, las cuales tenían entre 4-6 días de edad y provenían de plantas de acelga. Una vez finalizada la experiencia, se contabilizó el número de punciones de alimentación en cada una de las tres especies de plantas. Los ensayos fueron realizados en el Centro de Investigaciones Entomológicas de Córdoba, Argentina, en noviembre de 1999.
El número de punciones es una variable discreta que no posee valores negativos y tiene una distribución del tipo Poisson. Para introducirla en el ML, se realizó la transformación logarítmica de la respuesta (Ln (y+1)), lo que permite contraer la distribución,"normalizarla" y homogeneizar las varianzas (Zar 1996). El MLG toma directamente la variable con distribución Poisson asumiendo, entre otras cosas, que se incrementa la varianza al aumentar la media. Para este modelo se utilizó la función de enlace Ln (McCullagh & Nelder 1989).
Para contemplar la posible preferencia ocasionada sólo por la conspicuidad del hospedador, la superficie foliar se incorporó al análisis de la variable "número de punciones" de dos formas: en un primer caso, como una covariable y también como una variable compensadora ("offset"). Se considera variable compensadora a una constante que se agrega al modelo (Littel et al. 1996); en este caso, el valor de la superficie foliar de cada planta. La incorporación de la superficie foliar como variable compensadora, resulta mas realista ya que permite asignarle al modelo el valor de superficie correspondiente a cada unidad, mientras que las covariables asumen el supuesto de la falta de interacción tratamiento-covariable, modelando sólo una pendiente para todos los tratamientos (McCullagh & Nelder 1989). Por otro lado, se relativizó el número de punciones en función de la superficie de la hoja, creando una nueva variable denominada 'número de punciones/ cm²'.
Los datos fueron analizados con dos modelos mixtos que contemplan la covariación entre las unidades de observación: Análisis de Devianza (MLG mixto: Lµ i = µ + αi) y Análisis de la Varianza (ML mixto: Ln yi = µ+ αi + εi); y dos modelos en los que cada jaula entomológica se consideró un bloque: Análisis de la Varianza con bloque al azar (Ln yij = µ + αi + βj + εij) y Test de Friedman (Análisis de la Varianza con bloques, no paramétrico). Además, para el análisis del número de punciones con MLG mixto, se incorporó la superficie foliar como covariable (Ln µi= µ + αi + β área ) y como variable compensadora (Ln µi = Ln área + µ + αi).
Para estimar la correlación existente entre las plantas dentro de una misma jaula, se utilizó el modelo de simetría compuesta, considerado como uno de los más parsimoniosos porque estima sólo un parámetro. En este modelo, la matriz de correlación está formada por una diagonal principal con valores uno, que indica la correlación de un tratamiento consigo mismo, y solo un valor de correlación estimado para el resto de los tratamientos dentro de la jaula (Littel et al. 1996). Para probar las diferencias entre los tratamientos, se realizaron contrastes, con excepción del Test de Friedman para el cual se realizaron comparaciones múltiples mediante el test de Dunn (Zar 1996). El comportamiento de los modelos utilizados se evaluó mediante comparaciones de la magnitud de los intervalos de confianza obtenidos en cada análisis para cada una de las variables consideradas. Si la potencia de un test (1-β) es la capacidad de rechazar una hipótesis nula falsa (Mood & Graybill 1978), el modelo que presente intervalos más reducidos será considerado el mejor estimador o el más potente.
Los análisis fueron realizados utilizando el procedimiento GENMOD de SAS 8.01 (SAS Institute 1988).
RESULTADOS Y DISCUSIÓN
El número de punciones alimenticias (por planta y por superficie) realizado por las hembras de L. huidobrensis fue, en promedio, superior en haba, seguido por poroto y zapallito. La superficie foliar fue mayor en zapallito, seguido por haba y poroto (Tabla 1). Los modelos utilizados en el análisis de los datos provenientes de las pruebas de preferencia, detectaron diferencias significativas entre las medias de las variables consideradas en todos los casos, excepto al incorporar la superficie como covariable al análisis de devianza del número de punciones (Tabla 2). Sin embargo, al determinar entre cuales de los tratamientos había diferencias mediante los contrastes y el test de Dunn, la respuesta de los distintos modelos fue diferente (Tabla 3).
Tabla 1. Número de punciones por planta y superficie (media y desvío estandar) efectuadas por hembras de L. huidobrensis y superficie foliar de las distintas plantas hospedadoras. Valores registrados en las pruebas de preferencia de elección múltiple.
Table 1. Number of punctures per plant and surface (mean and standard deviation) performed by L. huidobrensis females and foliar surface of the different host plants. Values registered in the multiple choice preference tests.
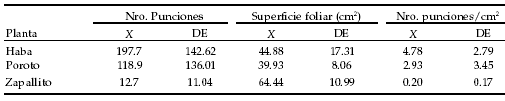
Tabla 2. Resultados del análisis de las variables de preferencia obtenidos con los distintos modelos. CE = valor de correlación estimada.
Table 2. Results of the analysis of the variables of preference obtained through the different models. CE = estimated correlation value.

Tabla 3. Resultados, para cada uno de los modelos considerados, de los contrastes entre las medias del número de punciones por planta y por superficie foliar realizadas por L. huidobrensis en las distintos hospedadores. Se muestran los valores de los estadísticos (X² y F) y de probabilidad (P) para cada contraste. H = haba, P = poroto y Z = zapallito.
Table 3. Results, for each of the studied models, of the contrasts between the means of the number of punctures per plant and foliar surface performed by L. huidobrensis in the different host plants. The statistics (X² y F) and probability (P) values for each contrast are shown. H = broad bean, P = bean and Z = courgette.

En los contrastes del número de punciones alimenticias realizados con el MLG, no se observaron diferencias significativas entre haba y poroto, siendo ambos hospedadores preferidos a zapallito. En cambio, los efectuados con ML mixto y ANOVA con bloques detectaron diferencias en todos los casos, siendo haba preferido a poroto y ambos a zapallito (Tabla 3). Esta discrepancia en los resultados de los contrastes se debió a que en estos últimos modelos se trabajó con los logaritmos de la variable. Cuando en el marco de la inferencia estadística se utilizan datos transformados debe tenerse especial cuidado en la interpretación de los resultados. Las transformaciones logarítmicas no son lineales, lo que significa que la media de la variable original no es igual a la media de los Ln (y) re-transformada. Si bien la utilización de este tipo de transformaciones de la variable está ampliamente difundida, el alcance biológico o ecológico de encontrar diferencias entre medias de logaritmos debiera examinarse con mayor profundidad. El test de Dunn, realizado a posteriori del Test de Friedman, no detectó diferencias significativas entre haba y poroto, pero si entre éstos y zapallito (Tabla 3).
Al incorporar al modelo de análisis de devianza la superficie foliar como una covariable, se obtuvieron resultados contrapuestos a los observados utilizando la variable compensadora (Tabla 2). En el primer caso, si bien la covariable no resultó significativa (χ² = 0.57, g.l. = 1 y P = 0.4486), no se registraron diferencias entre hospedadores. Mientras que en el segundo caso, haba y poroto fueron preferidos a zapallito, aunque no presentaron diferencias significativas entre sí (Tabla 3).
El análisis de la variable 'número de punciones por superficie' mediante ANOVA con covarianzas estimadas (ML Mixto) y con bloques al azar, arrojó valores F iguales para ambos modelos debido a que se trabajó con un solo factor (Tabla 2 y 3). Las conclusiones cambiarían si se trabajara con más de uno. Por otra parte, muchos programas estadísticos no presentan la opción de colocar factores aleatorios, por lo que constituiría un recurso válido la utilización de bloques como forma de reemplazarlos. Sin embargo, si se desconoce el grado de dependencia que está asociando a los tratamientos dentro de una caja y la covarianza estimada entre ellos fuera elevada, la utilización de bloques fijos no sería conveniente.
En los contrastes realizados para los distintos modelos y en las comparaciones múltiples efectuadas para el test de Friedman, se obtuvo el mismo resultado: haba y poroto resultaron preferidos a zapallito, pero no presentaron diferencias significativas entre sí (Tabla 3). Si bien la utilización de los modelos considerados permitió contemplar la dependencia de los datos, la potencia de cada uno de ellos fue diferente (Tabla 4). La performance de los distintos modelos estadísticos frecuentemente es evaluada siguiendo criterios de comparación como Akaike (1974) o Schwartz (1978). Estos métodos solo permiten cotejar modelos que utilicen la misma variable respuesta. En este estudio, se realizaron transformaciones logarítmicas de las variables para incorporarlas a los ML y resultaría inapropiado utilizar los métodos mencionados anteriormente. Por esta razón, la comparación de los modelos se realizó mediante la amplitud de los intervalos de confianza. La amplitud del intervalo obtenida con el MLG mixto para el número de punciones con la superficie foliar como variable compensadora, se comparó con las amplitudes de los modelos utilizados para el análisis de la variable número de punciones/ cm². Esto, debido a que los resultados obtenidos en aquel modelo se hallaban expresados en esas unidades.
Tabla 4. Valores del estimador puntual (media o mediana) (E.P.), límite inferior (LI) y superior (LS) del intervalo y amplitud de este último (A.I.) obtenidos en los distintos modelos para la variable número de punciones por planta y por superficie foliar en plantas hospedadoras estudiadas. H = haba, P = poroto y Z = zapallito.
Table 4. Values of the punctual estimator (mean or median) (E.P.), lower (LI) and upper (LS) interval limits and interval amplitude obtained in the different models for the number of punctures per plant and foliar surface in the host plants studied. H = broad bean, P = bean and Z = courgette.
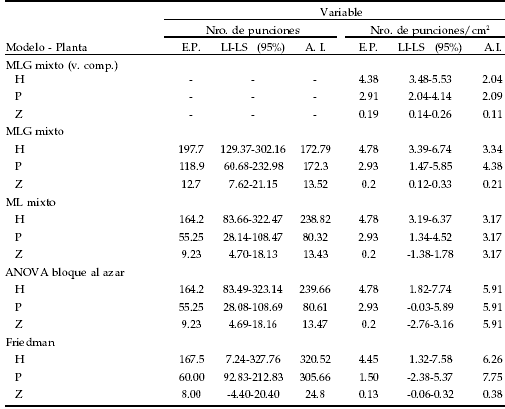
Los resultados obtenidos indican que es recomendable la utilización de modelos mixtos en las pruebas de preferencias con más de dos tratamientos, ya que éstos contemplan la dependencia existente entre ellos y son más potentes que los restantes modelos considerados en este trabajo. Los ML Mixtos son los más apropiados en el análisis de variables que posean distribución Normal, mientras que los MLG Mixtos son los más convenientes para aquellas con distribución Poisson (conteos) u otras de la familia exponencial (Tabla 4). Los ML que permiten la utilización de bloques aleatorios no presentan mayores complicaciones en su utilización y están disponibles en muchos paquetes estadísticos de uso corriente. Los programas que permiten trabajar con ML mixtos (con modelado de matriz varianza covarianza) y MLG requieren conocimientos más avanzados (e.g., SAS, Splus y R). Sin embargo, la tendencia es que estos modelos sean incorporados a los paquetes estadísticos de amplia difusión y fácil utilización.
El análisis de datos provenientes de pruebas de elección múltiple mediante modelos que no contemplan la dependencia entre tratamientos, es muy frecuente en trabajos sobre preferencia. Los resultados y, consecuentemente, las conclusiones varían cuando dicho análisis es realizado con distintos métodos (Tabla 3). La utilización de modelos estadísticos adecuados y potentes, como los ML y MLG mixtos, podría contribuir a una mayor comprensión de la utilización selectiva de los recursos por parte de los organismos.
AGRADECIMIENTOS
Al Dr. R. Macchiavelli por las sugerencias realizadas al manuscrito y por su ayuda con el programa SAS v 8.01.
BIBLIOGRAFÍA
Akaike, H. 1974. A New look at the statistical model identification. IEEE Trans. Atomat. contr. 19(6):716- 723. [ Links ]
Graybill, F. 1976. Theory and application of the linear models. Wadsworth & Brooks/Cole. Pacific Grove. EEUU. 705 pp. [ Links ]
Karban, R & G English-Loeb. 1997. Tachinid parasitoids affect host plant choice by caterpillars to increase caterpillar survival. Ecology 78(2):603-611. [ Links ]
Kuehl, R. 2001. Diseño de Experimentos. Principios estadísticos para el diseño y análisis de investigaciones.Thomson Learning. México DF. 666 pp. [ Links ]
Littel, RC; GA Milliken; WW Stroup & RD Wolfinger. 1996. SAS System for Mixed Models. SAS Institute. Cary, EEUU. 779 pp. [ Links ]
Manly, BFJ. 1993. Comments on design and analysis of multiple-choice feeding-preference experiments. Oecologia 93(1):149-152. [ Links ]
Mayhew, PJ. 1998. Testing the preference-performance hypothesis in phytophagous insects: lessons from Chrysanthemum leafminer (Diptera: Agromyzidae). Env. Entomol. 27(1):45-52. [ Links ]
McCullagh, P & J Nelder. 1989. Generalized Linear Models. Chapman & Hall. Londres. 511 pp. [ Links ]
Mc Millin, JD & MR Wagner. 1998. Influence of host plant vs. natural enemies on the spatial distribution of a pine sawfly. Neodiprion autumnalis. Ecol. Entomol. 23:397-408. [ Links ]
Mood, A & F Graybill. 1978. Introducción a la teoría de la estadística. Aguilar. Madrid, España. 536 pp. [ Links ]
Peterson, CH & PE Renaud. 1989. Analysis of feeding preference experiments. Oecologia 80(1):82-86. [ Links ]
Piepho, HP & J Ogutu. 2002. A simple mixed model for trend analysis ind wildlife populations. J. agric. biol. environ. stat. 7(3):350-360. [ Links ]
Poore, AGB & PD Steinberg. 1999. Preference-performance relationships and effects of host plant choice in an herbivorous marine amphipod. Ecol. Monogr. 69(4):443-464. [ Links ]
Roa, R. 1992. Design and analysis of multiple-choice feeding-preference experiments. Oecologia 89(4):509-515. [ Links ]
SAS Institute. 1988. SAS/STAT user´s guide, released 8.01 edition. SAS Intitute Inc. Cary. [ Links ]
Schwartz, G. 1978. Estimating the dimension of a model. Ann. Statistic. 6(2):461-464. [ Links ]
Spencer, KA. 1973. Agromyzidae (Diptera) of economic importance. Ser. Entomol 9:1-418. [ Links ]
Steinbauer, MJ; AR Clarke & JL Madden. 1998. Oviposition preference of a Eucalyptus herbivore and the importance of leaf age on intraspecific hos choice. Ecol. Entomol. 23:201-206. [ Links ]
Stuart, RJ & S Polavarapu. 1998. Oviposition preferences of the polyphagous moth Choristoneura parallela (Lepidoptera: Tortricidae): Effects of plant species, leaf size, and experimental design. Environ. Entomol. 27(1):102-109. [ Links ]
Weintraub, PG & AR Horowitz. 1995. The newest leafminer pest in Israel, Liriomyza huidobrensis. Phytoparasitica 23(2):177-184. [ Links ]
Zar, J. 1996. Biostatistical analysis. Prentice-Hall. New Jersey, EEUU. 662 pp. [ Links ]

