











 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink¿Los pronósticos de un modelo predictivo desarrollado previamente son válidos para mis pacientes? Esta es una pregunta difícil que se trató cuidadosamente en un estudio reciente focalizado en la validez del puntaje GRACE para predecir mortalidad hospitalaria. 1
¿Porqué es importante este estudio de gran calidad de Mangariello y Gitelman? En la literatura médica, existe un creciente número de publicaciones sobre modelos predictivos. Se proponen nuevos métodos, como aprendizaje automático con datos clasificados, aprendizaje automático profundo, e inteligencia artificial. Independientemente del método de desarrollo, el problema central es si el modelo o algoritmo predictivo proporciona pronósticos válidos a los médicos y a sus pacientes que dependen de ellos como fuente de información y para la toma de decisiones. De hecho, los autores plantean que pueden existir muchas diferencias en distintos ámbitos. Estas incluyen diferencias en las características de los pacientes, los sistemas de salud, y el contexto socioeconómico, además de cambios en el tratamiento a lo largo del tiempo. Todas estas diferencias pueden hacer que un modelo desarrollado previamente no sea válido para el entorno en particular donde se aplica el modelo, por ejemplo el Hospital Dr. Juan A. Fernández en Buenos Aires, siendo necesaria su actualización para ese contexto específico. 2
Validación: ¿cómo y por qué?
¿Cómo se debería realizar una validación? El primer problema es si es esperable que un modelo desarrollado con anterioridad sea aplicable a un grupo de validación. El trabajo presentado incluyó pacientes de dos centros en Argentina en el desarrollo del modelo internacional GRACE. Por lo tanto, es probable que el grupo de validación estuviera relacionado con el grupo de desarrollo. Además, el modelo incluía un conjunto clínicamente razonable de predictores, y había sido propuesto por un grupo internacional de expertos.
La guía TRIPOD proporciona más elementos para llevar a cabo una validación, especialmente en su detallado documento de Explicación y Elaboración. 3 Los elementos importantes para la validación incluyen un tamaño de muestra adecuado y métodos apropiados.
Tamaño de la muestra: Un tamaño de muestra adecuado implica al menos 100 eventos en la validación. 4 Por lo tanto, si la mortalidad hospitalaria es del 5%, se necesita un tamaño de muestra de al menos 2000 pacientes para obtener resultados confiables. También, los datos faltantes pueden ser imputados mediante métodos estadísticos avanzados para hacer uso completo de toda la información disponible, aún en el caso de que haya algunos registros de pacientes incompletos. Ambas condiciones se cumplieron en el presente estudio para el grupo total de pacientes (2104 pacientes, 117 eventos). 1 Sin embargo, el tamaño de la muestra fue un factor limitante en el subgrupo de SCA noST, con solo 35 eventos. En consecuencia, es imposible separar un desempeño aparentemente adecuado de la falta de potencia para detectar uno incorrecto.
Métodos adecuados: Los aspectos clave son la capacidad discriminatoria y la calibración. 2. Generalmente, la discriminación se evalúa por medio del área bajo la curva ROC (ABC), también llamada concordancia o estadístico c. La calibración evalúa si los riesgos estimados concuerdan con la frecuencia del evento. Los autores enfatizan correctamente la evaluación gráfica por sobre la prueba estadística. Si queremos evaluar la capacidad de un modelo de guiar la toma de decisiones, se necesitan medidas más modernas, incluyendo el “Beneficio Neto”. 5 Este último acepta el número de clasificaciones de datos verdaderos positivos y penaliza las clasificaciones de falsos positivos, cuando separamos aquellos pacientes de riesgo alto versus bajo mediante un modelo predictivo. El peso relativo está definido por el contexto clínico, lo cual es mejor que utilizar un peso estadístico. 6
Interpretación y consecuencias de la falta de validez
¿Cómo debemos interpretar los resultados? El puntaje GRACE fue bien desarrollado. El modelo tiene validez interna adecuada, sin riesgos de sobreestimación ya que el tamaño de la muestra fue muy grande (Tabla 1), pero obviamente está lejos de ser perfecto para predecir quienes van a morir y quienes no, y puede ser inapropiado para grupos específicos de pacientes. La validación externa de este trabajo confirma que la capacidad discriminatoria sigue siendo adecuada cuando el modelo se aplica en otro entorno. El ABC fue de 0.83 en el desarrollo del modelo y de 0.87 en la validación externa, 1 lo cual es atribuible a una mayor heterogeneidad [variabilidad de los valores predictores entre pacientes: “mezcla de casos” (“case-mix”)]. 2
Tabla 1 Síntesis de los principales problemas de validez interna y externa de modelos predictivos clínicos. 2
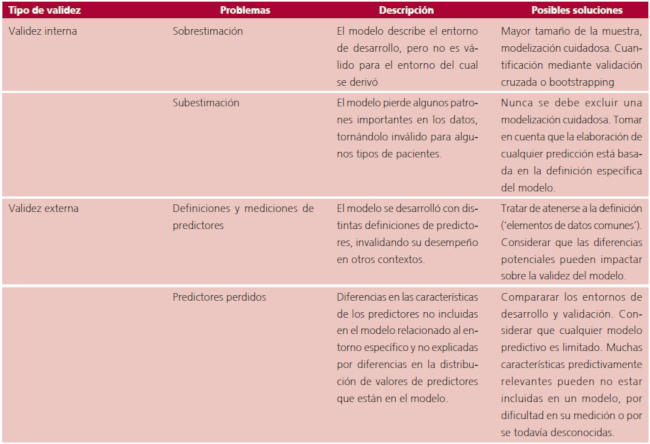
La calibración de las predicciones es el aspecto de la validez más relevante para pacientes individuales y es el talón de Aquiles de los modelos predictivos. 7 En el estudio de validación presentado, los resultados fueron peores que lo esperado, lo cual puede tener dos interpretaciones muy diferentes. Uno es que el cuidado fue subóptimo en el entorno de la validación. El otro es que el modelo fue inadecuado debido a que algunos predictores que fueron diferentes en el contexto de la validación en comparación con el entorno de desarrollo no fueron incluidos en el modelo (Tabla 1). Por lo tanto, pueden existir diferencias en el riesgo basal entre los entornos de desarrollo y validación que no fueron capturados por el modelo. 1,2 ¿Podemos aplicar entonces, el modelo GRACE en este hospital específico, en Argentina, en Sudamérica? Los resultados de validación de este estudio apoyan el concepto de un modelo global, con efectos predictores que son ampliamente válidos. (8) Sin embargo, su aplicación local requiere de actualización al entorno específico. Un enfoque simple consiste en actualizar el modelo cruzándolo con un modelo local, de modo que las predicciones sean en promedio correctas. (8,9) Nuevos enfoques para ese tipo de actualización necesitan cuidado, junto con la disponibilidad de una recolección de datos mucho más rutinaria y el deseo de utilizar sistemas de autoaprendizaje. (10) Estas predicciones más actualizadas apoyarán la toma de decisiones y contribuirán a mejorar los resultados de pacientes individuales.

