










Servicios Personalizados
Revista

Articulo
 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista industrial y agrícola de Tucumán
versión On-line ISSN 1851-3018
Rev. ind. agric. Tucumán vol.87 no.2 Las Talitas jul./dic. 2010
ARTÍCULOS ORIGINALES
Statistical modeling of sugar cane potential bud sprouting within the context of a 3x3x2 factorial experiment
Osvaldo E. A. Arce*, Patricia A. Digonzelli** and Eduardo R. Romero**
*Cátedra Biometría y Técnica Experimental de la Facultad de Agronomía y Zootecnia, UNT. ova.arce@gmail.com
**Sección Caña de Azúcar, EEAOC
Abstract
The aim of this study was to model sugarcane potential bud sprouting temporal evolution within the context of a 3x3x2 factorial experiment. Statistical modeling was accomplished by means of a three-parameter logistic model using nonlinear mixed models. The trial was carried out with seed cane from three varieties (LCP 85-384, CP 65-357 and CP 48-103), considering three harvesting dates (May, August, and October) and two seed cane origins (micropropagation and hot water treatment). Experimental units were distributed in a 3x3x2 completely randomized factorial arrangement with two replicates. The number of sprouts was recorded from the day after plantation up to the 21st day. The selection of effects associated with a particular parameter was made by means of backward selection. Once the significant effects were selected, the need for the corresponding random effect was tested. The same procedure was followed with the rest of the parameters. Heteroscedasticity was corrected using a power variance function and autocorrelation of residuals was included as an order 1 autoregressive model. After statistical modeling, the conclusion to be drawn is that the methodology of nonlinear mixed models is an adequate and powerful tool when analyzing data obtained from factorial experiments, where repeated measurements over a period of time have been recorded.
Key words: Mixed models; Repeated measurements; Nonlinear models; Growth curves; R.
Resumen
Modelado estadístico de la brotación potencial de caña de azúcar en un experimento factorial 3x3x2
El objetivo del trabajo fue modelar la evolución temporal de la brotación potencial en caña de azúcar, en el contexto de un experimento factorial 3x3x2. El modelado se hizo mediante el modelo logístico de tres parámetros, utilizándose modelos mixtos no lineales. Se trabajó con caña semilla de tres variedades (LCP 85-384, CP 65-357 y CP 48-103), tres épocas de cosecha (mayo, agosto y octubre) y dos orígenes de la semilla (micropropagación y propagación convencional por estacas termotratadas). Las unidades experimentales se ubicaron en un arreglo factorial 3x3x2 completamente aleatorizado con dos repeticiones. Se registró diariamente el número de yemas brotadas, desde el día siguiente al de plantación hasta los 21 días. En modelos mixtos, la selección de los efectos asociados con un parámetro particular se hizo mediante una selección hacia atrás. Una vez seleccionados los efectos significativos, se evaluó si el efecto aleatorio correspondiente era necesario. El mismo procedimiento se siguió con el resto de los parámetros. La heterocedasticidad se corrigió mediante una función de potencia de varianza, y para la autocorrelación de residuales se usó un modelo autoregresivo de orden 1. Luego del análisis, se concluye que el empleo de la metodología de modelos mixtos no lineales es una herramienta adecuada y poderosa para el análisis de datos obtenidos en experimentos factoriales donde se realizan mediciones repetidas cada cierto intervalo de tiempo.
Palabras clave: Modelos mixtos; Factorial con medidas repetidas; Modelos no lineales; Curvas de crecimiento; R.
Introduction
Some agricultural trials are based on factorial experiments in which a combination of factors is assigned to each experimental unit and subsequently, repeated measurements over time are recorded within each of them. The researcher's interest is focused on modeling the functional form of response over time, considering the factorial structure of the trial.
Statistical analysis of such data may be complex within the context of a factorial experiment, because fitting curves have to be estimated for every replicate within each combination of the factor levels under consideration. The main interest in this case is to determine whether significant differences these authoes among the estimated curve parameters at the level of principal effects and/or interactions among factors.
Anderson and Dusky (1986) introduced a methodology for the analysis of such data fitting logistic and Gompertz models. Data corresponded to eight treatments to stimulate sugarcane stalk sprouting, combined with three different temperatures. The methodology proposed by them consisted in fitting individual curves for every replicate in each treatment-temperature combination. Once the estimates were obtained, an analysis of variance for every estimated parameter was performed and Duncan's post-hoc pairwise comparison test was applied. The analysis of variance was performed for the eight sprout-stimulating treatments separately in relation to each temperature, i.e. the factorial nature of the experiment was not taken into account. Interactions were not estimated. Besides, the assumptions on which the analysis of variance is based were not checked: homoscedasticity, normality and independence of residuals (Faraway, 2006). Positively correlated residuals generate a lower actual precision for means than the precision estimated by analysis of variance. Heteroscedasticity and non-normality produce lower or higher signification values than the actual ones (Kuehl, 2001).
An alternative to this methodology is to use nonlinear mixed models. This approach allows estimating fixed effects, which represent the parameter mean values in the population of experimental units, and random effects, which encompass individual deviations of each experimental unit from those mean values (Pinheiro and Bates, 2000). Even when the interest is focused on estimating the parameters of the population curves (fixed effects), this methodology fits individual curves (or within groups fitted values) for each experimental unit. This is typical of mixed-effects estimation: the individual coefficient estimates represent a compromise between the coefficients from the individual fits and the fixed effect estimates, associated with population averages. For this reason, these estimates are often called shrinkage estimates, in the sense that they shrink the individual estimates toward population average. Besides, the pooling of experimental units gives a certain amount of robustness to individual outlying behavior (Pinheiro and Bates, 2000).
Since the 90s, developments in computer technology and methodologies have provided powerful and flexible data analysis tools. Nonlinear mixed models allow the inclusion of the effect of covariables which account for variability in estimated coefficients in the fitted model, and at the same time, they account for the structure of random effects and correlation within each experimental unit determined by multiple measurements over time. They also permit correction of pathologies in the residuals which may affect a proper inference, such as correlation and/or heteroscedasticity.
Initially, this methodology was used in studying problems related to medicine, chemistry and social sciences. In agricultural sciences, it has been widely used in animal and plant breeding. In sugarcane breeding, papers by Pereira Barbosa et al. (2004) and Vilela de Resende et al. (2006) can be cited. Moral and Arnhold (2006), Moral and Scapim (2007) and So and Edwards (2009) also used mixed models in maize breeding.
Linear and nonlinear growth models have been used in research on citrus (Avanza et al., 2008) and forestry (Galíndez et al., 2007; Carrero et al., 2008).
Data from repeated measurements from factorial experiments in sugarcane were analyzed by Glaz and Gilbert (2006) and Glaz et al. (2004) using linear mixed models.
Estimating algorithms for these models were implemented in SAS (Littel et al., 1996) and more recently in S-plus and R (Pinheiro et al., 2009). Examples and theoretical aspects of linear and nonlinear mixed models can be found in Vonesh and Chinchilli (1997), Pinheiro and Bates (2000), Verbeke and Molenberghs (2000), Venables and Ripley (2002), Maindonald and Braun (2003), Faraway (2006) and Crawley (2007).
A revision of nonlinear models may be found in Ratkowsky (1989). Pinheiro and Bates (2000) introduce several models to be applied to growth curves: three- and four-parameter logistic and Gompertz and Weibull models, among others.
The freely distributed software R (R Development Core Team, 2009) includes the library nlme (Pinheiro et al., 2009), introducing powerful and very flexible graphical and inferential tools for mixed models.
SAS has been widely used so far. Neither references for sugarcane using R, nor reports of the modeling of curves in factorial experiments with more than two factors, have been found.
An interesting book dealing with the comparison of linear mixed models analysis conducted with softwares SAS, R, SPSS, Stata and HLM was written by West et al. (2007).
The aims of this study are to analyze sugarcane potential bud sprouting within the context of a 3x3x2 factorial experiment, using the methodology of nonlinear mixed models with logistic fit, and to evaluate the adequacy of this methodological approach using the statistical software R.
Material and methods
Data were obtained from a trial planted in a field that belongs to Cátedra de Caña de Azúcar, in Finca El Manantial (Facultad de Agronomía y Zootecnia– Universidad Nacional de Tucumán, Argentina). Seed cane bud sprouting capacity under optimal humidity and temperature conditions was evaluated. Seed cane from three varieties (LCP 85-384, CP 65-357 and CP 48-103), three harvesting dates (May, August, and October) and two seed cane origins (micropropagation and hot water treatment) were considered. The experimental design was a factorial design with three factors (variety, harvesting date and origin). Three levels were taken into account for the first and second factors, and two levels for the third one. Experimental units were distributed in a 3x3x2 completely randomized factorial arrangement with two replicates.
Thirty uninodal stalks were planted in trays with washed and sterilized sand. Each tray corresponded to an experimental unit. The number of bud sprouts was recorded from the day after plantation up to the 21st day.
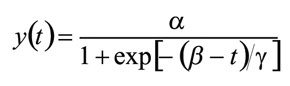 equation 1
equation 1
In this model when γ >0, α is the horizontal asymptote when t → ∞ and 0 is the horizontal asymptote when t → -∞. The parameter β is the value of t for which the proportion of sprouts is α/2. This is the curve inflection point. The scale parameter γ represents the distance on t axis between this inflection point β and the point for which the response is α/(1+e-1) » 0.73 α. t represents time (the moment at which the observation was recorded). This is a symmetric model.
Asymmetric sigmoid models, such as Gompertz (Equation 2), have been used as well (Avanza et al., 2008; García and Col, 2005).
 equation 2
equation 2
In Gompertz model, α is the horizontal asymptote when t → ∞, β is the population growth rate and γ is related to the beginning of population growth.
Overparameterized models (individual parameters for each tray) were fitted for both logistic and Gompertz curves using the procedure nlsLIST in R. Residual standard errors resulted almost identical (logistic = 0.0326; Gompertz = 0.0330), indicating that either of them could be used with the data. Since logistic fit parameters are more meaningful when analyzing sprouting processes, the former model was chosen in this paper.
The analysis strategy suggested by Pinheiro and Bates (2000) was followed. This strategy focuses on the principle of parsimony, i.e. looking for the best model, which is the one comprising the lesser number of parameters.
Once the curve fittings for individual experimental units were obtained, the estimated parameters were evaluated to determine which random effects should be included in the model.
Data were obtained from a factorial experiment with three factors. It was thus necessary to find those fixed effects (main effects and interactions), corresponding to the covariables to be included in the model, which would account for the variation in the three parameters of the logistic model mentioned above.
The first stage was to determine the components of the fixed part of the model. A backward selection procedure was used for each of the three parameters, one at a time. That is, for a certain parameter the starting point was a full model with main effects, double and triple interactions. Non-significant effects were eliminated following the hierarchy principle, i.e. a low order non-significant effect was kept in the model if that effect was included in a significant effect of a higher order. The significance of fixed effects associated with a covariable included in the model was evaluated using Wald type tests.
Once all the effects included for a certain parameter were determined, the same procedure was followed for the other two parameters. A combined strategy was used: backward selection within a certain parameter and forward selection when moving from one parameter to the others.
Once the fixed part was determined, the second stage consisted in evaluating the need to include random effects and their correlation structure. After adjusting the random part of the model, the significance of fixed effects had to be retested. This is due to the fact that some changes were introduced with respect to the results obtained at the first stage of the analysis.
Nested models were evaluated by means of likelihood ratio tests and the Akaike and Bayesian information criteria (AIC and BIC, respectively).
The final step was to verify model assumptions.
The statistical software R was used (R Development Core Team, 2009), namely, packages nlme (Pinheiro et al., 2009) and lattice (Sarkar, 2008 and 2010). Lattice graphic package, combined with nlme procedures, creates very useful graphics to evaluate the quality of fitted models, as well as diagnostic plots to evaluate model assumptions.
Fitted models were evaluated by using several diagnostic tools: graphical analyses of random effects (qqplot) and residuals (qq plots, predicted vs fitted values, residuals vs factors for heterocedasticity and autocorrelation functions), signification of parameters, magnitude of the residual variance, amplitude of confidence intervals for parameter estimations and the classical adjusted R2 criteria used in regression.
Some other nonlinearity measures, such as the ones presented by Bates and Watts (1980), allow quantifying departure from linearity of a set of data model-parameterizations and the estimation of Box bias (Ratkowsky, 1989; Montgomery et al., 2004). For calculation of the nonlinearity measures and the bias estimators, a program was developed by Bramardi et al. (1997), which uses SAS software IML procedure (SAS Institute, 2000). These procedures have not been implemented yet in the R package nlme. In this paper only tools available at this moment in R were used to evaluate the adequacy of the models.
Results and discussion
Observed data are shown in Figure 1. Sprouting is expressed as proportions (percentage divided by 100) to assimilate the figures to a probability value. An important variability is observed among experimental units. Some treatments present a more pronounced lineal intermediate phase indicating that maximal sprouting is reached faster. Curves initiate in 0 and the asymptote is 1 (100% sprouting) in most of the treatments.

Figure 1. Proportion of bud sprouts over time in seed cane from three varieties, two origins (v= vitroplants, c= hot water treatment) and three harvesting dates.
Figure 2 shows 95% confidence intervals for parameters of the logistic model fitted individually for each experimental unit. According to the figure, a random component should be taken into account for each parameter of the model, with α showing lesser variability. Parameter c exhibits a systematic effect with lower values in August. No other effects are observed graphically.

Figure 2. Ninety-five per cent confidence intervals for parameters of the logistic model fitted individually to each experimental unit. Numbers indicate varieties (LCP 85-384, LCP 65-357 and CP 48-103) and 1 and 2 indicate the replicate. v = vitroplants and c= hot water treatment.
Using this preliminary information, a first model without covariables was fitted in order to clarify the structure of random components. This model is expressed in Equation 3.
 equation 3
equation 3

Where:
Y: is a general positive definite matrix,
yij: is the measurement in the experimental unit i at moment j.
tij: represents time j in experimental unit i.
Fixed effects β represent the mean value of individual parameters ji, and random effects bi represent deviations from those mean values.
The results obtained are shown in Table 1.
Table 1 shows that the least important random effect is the one corresponding to the asymptote (standard deviation = 0.0637922). The result of the likelihood ratio test comparing a model with random α, b and c components and another one with only b and c was significant (likelihood ratio = 342.27, 10 and 7 df respectively, p < 0.0001), indicating that random effect for α should be included. The correlation matrix of random effects (right bottom in Table 1) shows that a general positive definite structure seems to be appropriate at this stage of the modeling process. This is an initial structure, since the inclusion of the covariables as fixed effects may change the random part of the model.
The inclusion of varieties, origins and harvesting dates as covariables and the corresponding interactions for each parameter, one at a time in a backward selection, were accomplished using the methodology detailed in the Material and Methods section and keeping the initial structure for random components. The results are shown in Table 2.
Table 1. Estimates for the model corresponding to Equation 3.

Table 2. Wald type tests for the fixed part of the model with random effects for the three parameters (a, b, and c) and general positive definite structure for Y.

The model includes random effects for the three parameters and general positive definite structure for Y.
Table 2 shows significant effects on the three parameters α, b and c.
The presence of significant main effects and interactions for α does not seem to be reasonable, since all experimental units (except one of them) reach 100% sprouting or a value very close to it.
Considering that the random part of the model seems to be correctly specified, residuals were analyzed to detect some pathology that could be affecting the inference (Figure 3). The assumption that the residuals are ![]() is not feasible for these data, so a more general structure should be considered, i.e.
is not feasible for these data, so a more general structure should be considered, i.e. ![]()

Figure 3. Standardized residuals against fitted values for each experimental unit. Numbers indicate varieties (LCP 85-384, LCP 65-357 and CP 48-103) and 1 and 2 indicate the replicate. v = vitroplants and c= hot water treatment.
Figure 3 shows mild heteroscedasticity in some of the experimental units. A pattern is observed also in higher and lower values than in the ones in the middle.
Figure 4 reveals a significant order 1 autocorrelation. The two situations mentioned above (residuals autocorrelation and heterocedasticity) made it necessary to include these effects in the model.

Figure 4. Autocorrelation function of residuals up to lag 13.
Heterocedasticity was modeled by means of a power variance function, using fitted values as the variance covariable (Pinheiro and Bates, 2000).
The likelihood ratio tests revealed that the new error structure improved the model significantly. After this adjustment, the fixed and random parts of the model were re-estimated.
Table 3 shows non-significant correlations leading to a simplification of the correlation structure of random effects into a block diagonal structure. The likelihood ratio tests indicated that the model including this simpler structure was equivalent to the one including a general positive definite matrix.
Table 3. Matrix parameter estimations of variance – covariance random effects in the model with random effects for the three parameters, general positive definite structure for Y and correlation matrix of residuals, including heterocedasticity and order 1 autocorrelation. The significance of intervals is 95%. sd= standard deviation and cor= correlation; ns=non significant.
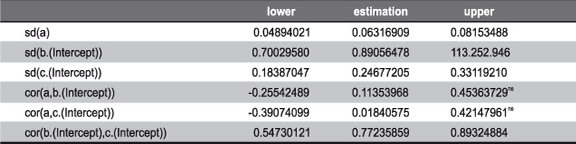
The results for the final model are shown in Tables 4 and 5.
Comparison of Tables 2 and 4 reveals that the correct specification of random effects and error covariance made effects associated with α non-significant. This result is coherent with the one displayed in Figure 1. Residuals were compatible with model assumptions (diagnostics not shown).
Table 4. Final fitted model Wald type tests (model with random effects for the three parameters, general positive definite structure for Y and correlation matrix of residuals, including heterocedasticity and order 1 autocorrelation).

Table 4 and Figure 5 show that the final fitted model is a good adjustment for these experimental data. The amplitude of confidence intervals presented in Table 5 confirms this fact. It has to be remarked that the observations in this trial were not independent within the experimental units. Any statistical analysis to be made on data like these, must take this fact into account.
Table 5. Estimations and 95% confidence intervals for the final model (random components). sd= standard deviation and cor= correlation.


Figure 5. Estimations and 95% confidence intervals for the final model (random components). sd= standard deviation and cor= correlation.
In the methodology proposed by Anderson and Dusky (1986), it is assumed that parameter estimations obtained from individual regressions in each experimental unit have the following characteristics: normal distribution, independence and constant variance within combinations of factors. These assumptions are feasible when data represent the realization of an observed process, but they are dubious when input data are parameters of curves fitted to a data set.
The mixed models in R approach (Pinheiro and Bates, 2000) allowed us to include all the situations mentioned throughout the paper (correlation of residuals, heterocedasticity and correlations among random factors) in the statistical modeling process. The F tests and parameter estimations were thus correct and constituted a powerful analysis tool.
Applying this methodology to the data enabled us to establish that final potential sprouting was similar in all treatments. Time needed to get 50% of sprouting b depends on variety and harvesting date, and scale parameter c depends on harvesting date and seed cane origin. A marginally significant variety x origin interaction was also found (6%).
Conclusions
The methodology of nonlinear mixed models turned out to be appropriate to analyze potential sugar cane sprouting dynamics, since it features enough flexibility to include all the characteristics of the data (fixed effects, random effects, correlations and heteroscedasticity), while enabling the inclusion of experiment factorial structure.
This paper intends to show the power and flexibility of non linear mixed models when curves are fitted to data within the context of a factorial experiment. Bud sprouting was used here just as a practical example of the use of this methodology. However, any nonlinear model may be modeled in a similar fashion using the model which is most appropriate to the particular experimental situation.
R is not the only software that can be used, as remarked in the Introduction section, but it is highly recommended as it is a free and very powerful tool.
This methodological approach should be applied when data are recorded within experimental units in successive non-independent evaluations over time.
Cited references
1. Anderson, D. L. and J. A. Dusky. 1986. Mathematical model interpretation of sugar cane bud germination. Sugar Cane 6: 6-10. [ Links ]
2. Avanza, M. M.; S. J. Bramardi and S. M. Mazza. 2008. Statistical models to describe the fruit growth pattern in sweet orange 'Valencia late'. Span. J. Agric. Res. 6 (4): 577-585. [ Links ]
3. Bates, D. M. and D. G. Watts. 1980. Relative curvature measures of nonlinearity. J. Statist. Soc. B 42: 1-25. [ Links ]
4. Bramardi, S.; M. L. Zanelli y H. R. Castro. 1997. Aplicación de medidas de no linealidad para la selección de modelos de crecimiento. Rev. SAE 1 (1): 39-52. [ Links ]
5. Carrero, O.; M. Jerez; R. Macchiavelli; G. Orlandoni y J. Stock. 2008. Ajuste de curvas de índice de sitio mediante modelos mixtos para plantaciones de Eucalyptus urophylla en Venezuela. Interciencia 33 (4): 266-272. [ Links ]
6. Crawley, J. 2007. The R Book. Editorial Wiley, New York. [ Links ]
7. Faraway, J. 2006. Extending the linear model with R. Generalized linear, mixed effects and nonparametric regression models. Chapman & Hall/CRC, Boca Raton, USA. [ Links ]
8. Galíndez, M. J.; A. M. Giménez; N. Ríos y M. Balzarini 2007. Modelación del crecimiento en diámetro de vinal (Prosopis ruscifolia) en Santiago del Estero, Argentina. For. Ver. 9 (2): 9-15. [ Links ]
9. García, M. y A. Col. 2005. Ajuste de una curva de crecimiento utilizando la función de Gompertz. FABICIB 9: 121-130. [ Links ]
10. Glaz, B. and R. A. Gilbert. 2006. Sugarcane response to water table, periodic flood, and foliar nitrogen on organic soil. Agron. J. 98: 616-621. [ Links ]
11. Glaz, B.; D. R. Morris and S. H. Daroub. 2004. Sugarcane photosynthesis, transpiration, and stomatal conductance due to flooding and water table. Crop Sci. 44: 1633-1641. [ Links ]
12. Kuehl, R. 2001. Diseño de experimentos. Thomson, México DF. [ Links ]
13. Littel, R. C.; G. A. Milliken; W. W. Stroup and R. D. Wolfinger. 1996. SAS system for mixed models. SAS Institute, Cary NC, USA. [ Links ]
14. Maindonald, J. and J. Braun. 2003. Data analysis and graphics using R. Cambridge University Press, Cambridge, USA. [ Links ]
15. Montgomery, D.; E. Peck and G. Vining. 2004. Introducción al análisis de regresión lineal. Continental, México DF. [ Links ]
16. Moral, F. y E. Arnhold. 2006. Inferencia Bayesiana y metodología de modelos lineales mixtos aplicados al mejoramiento del maíz. Cien. Inv. Agr. 33 (3): 217-223. [ Links ]
17. Moral, F. y C. Scapim. 2007. Predicción de valores genéticos del efecto de poblaciones de maíz evaluadas en Brasil y Paraguay. Agric. Téc. (Chillán) 67 (2): 139-146. [ Links ]
18. Pereira Barbosa, M.; H. M. D. Vilela de Resende; L. A. Peternelli; J. da Silveira; F. Lopes da Silva and I. Rodrigues de Figueiredo. 2004. Use of REML/BLUP for the selection of sugarcane families specialized in biomass production. Crop Breed. and Appl. Biotechnol. 4: 218-226. [ Links ]
19. Pinheiro, J. C. and D. M. Bates. 2000. Mixed-effects models in S and S-plus. Springer, New York, USA. [ Links ]
20. Pinheiro, J.; D. Bates; S. Debroy; D. Sarkar and the R Core Team. 2009. nlme: linear and nonlinear mixed effects models. R package version 3.1-96. [On line]. Available from http://CRAN.R-project.org/package=nlme (accessed March 18, 2010). R Foundation for Statistical Computing, Vienna, Austria. [ Links ]
21. Ratkowsky, D. A. 1989. Handbook of nonlinear regression models. Marcel Dekker Inc., New York, USA. [ Links ]
22. R Development Core Team. 2009. R: a language and environment for statistical computing. [On line]. Available from http://www.R-project.org. (accessed March 18, 2010). R Foundation for Statistical Computing, Vienna, Austria. [ Links ]
23. Sarkar, D. 2008. Lattice. Multivariate data visualization with R. Springer, New York, USA. [ Links ]
24. Sarkar, D. 2010. Lattice: lattice graphics. R package version 0.18-3. [On line]. Available from http://CRAN.R-project.org/package=lattice (accessed March 18, 2010). R Foundation for Statistical Computing, Vienna, Austria. [ Links ]
25. SAS Institute. 2000. SAS Version 8. SAS Institute Inc. Cary, NC, USA. [ Links ]
26. So, Y. and J. Edwards. 2009. A comparison of mixed-model analyses of the Iowa crop performance test for corn. Crop Sci. 49: 1593-1601. [ Links ]
27. Venables, W. N. and B. D. Ripley. 2002. Modern applied statistics with S. 4. ed. Springer, New York, USA. [ Links ]
28. Verbeke, G. and G. Molenberghs. 2000. Linear mixed models for longitudinal data. Springer, New York, USA. [ Links ]
29. Vilela de Resende, M. D. and M. H. Pereira Barbosa. 2006. Selection via simulated individual BLUP based on family genotypic effects in sugarcane. Pesqui. Agropecu. Bras. 41 (3): 421-429. [ Links ]
30. Vonesh, E. and V. Chinchilli. 1997. Linear and nonlinear models for the analysis of repeated measurements. Marcel Dekker, New York, USA. [ Links ]
31. West, B; K. Welch and A. Galecki. 2007. Linear mixed models. A practical guide using statistical software. Chapman and Hall/CRC, Boca Raton, USA. [ Links ]

