Serviços Personalizados
Journal

Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkAnclajes
versão On-line ISSN 1851-4669
Anclajes vol.23 no.1 Santa Rosa jan. 2019
http://dx.doi.org/10.19137/anclajes-2019-2312
DOI: 10.19137/anclajes-2019-2312
ARTÍCULOS
Estudios literarios y lectura distante: un primer acercamiento a la actualidad de la investigación en las revistas académicas argentinas
Literary Studies and Distant Reading: a First Approach to current research in Argentine Academic Journals
Estudos literários e leitura distante: uma primeira abordagem da atualidade da investigação nas revistas acadêmicas argentinas
Juan Manuel Lacalle
Universidad de Buenos Aires
Argentina
jmlacalle@filo.uba.ar
ORCID: 0000-0002-4162-638X
Mariano Alejandro Vilar
Universidad de Buenos Aires
Argentina
marianovilar@filo.uba.ar
ORCID: 0000-0002-8220-7165
Resumen: el propósito de este artículo es realizar un acercamiento panorámico al estado actual de los objetos de investigación de los estudios literarios en las revistas académicas de Argentina. Nuestra propuesta metodológica consiste en la utilización de herramientas desarrolladas en el ámbito de las humanidades digitales para llevar a cabo una lectura distante que nos permita tener una visión más abarcadora y federal del campo atendiendo a sus lineamientos generales y recurrencias temáticas. Con esta finalidad, tomamos como corpus una serie de publicaciones digitales de 2014 y 2015, vinculadas a los estudios literarios en las universidades argentinas, para obtener un mapeo de los intereses y enfoques dominantes. En términos generales, buscamos generar una primera aproximación e insumo que favorezca el diálogo entre investigaciones con objetos en común.
Palabras clave: Lectura distante; Revistas académicas; Estudios literarios; Siglo XXI; Argentina.
Abstract: the purpose of this article is to comprehensively approach the current state of research objects in the Argentinean academic literary journals. Our methodological proposal consists of the use of tools developed in the digital humanities field to carry out a distant reading that allows us to have a more encompassing and federal vision of the field according to its general guidelines and thematic recurrences. With this purpose, we take as a corpus a series of digital publications of 2014 and 2015, linked to literary studies in Argentine universities, to obtain a mapping of the dominant interests and approaches. In general terms, we seek to generate a first approximation and input that favors dialogue between investigations and objects in common.
Keywords: Distant lecture; Academic journals; Literary studies; Twenty-first century; Argentina.
Resumo: o propósito deste artigo é realizar uma abordagem panorâmica do estado atual dos objetos de pesquisa dos estudos literários nas revistas acadêmicas da Argentina. Nossa proposta metodológica consiste no uso de ferramentas desenvolvidas na área das humanidades digitais para levar a cabo uma leitura distante que nos permita ter uma visão mais abrangente e federal do campo, levando em conta suas diretrizes gerais e recorrências temáticas. Com esta finalidade, tomamos como corpus uma série de publicações digitais de 2014 e 2015, vinculadas aos estudos literários nas universidades argentinas, para obter um mapeamento dos interesses e enfoques dominantes. Em termos gerais, procuramos gerar uma primeira aproximação e material que favoreça o diálogo entre pesquisas com objetos em comum.
Palavras-chave: Leitura distante; Revistas acadêmicas; Estudos literários; Século XXI; Argentina
Introducción
El desarrollo de la lectura distante (distant reading), entendida como el uso intensivo de la informática para trabajar sobre corpus de gran tamaño, representa una de las innovaciones metodológicas más llamativas en el campo de los estudios literarios de los últimos años. Su empleo se ha abocado hasta ahora a dos aplicaciones principales. Por un lado, se ha utilizado dentro de lo que podríamos llamar la “sociología de la literatura” para estudiar cuantitativamente datos como, por ejemplo, la cantidad de impresos y ediciones de determinados géneros y su difusión en distintas regiones y ámbitos. Por otro lado, apunta a la construcción del texto literario, es decir, a la forma en la que allí aparecen distribuidos los términos que construyen historias y representaciones, tales como las vinculaciones afectivas ligadas a situaciones, espacios o personajes. Ambas perspectivas funcionan como complemento, más que como superación, de la close-reading.
El primero de estos enfoques ha producido, por el momento, resultados más interesantes, ya que el análisis formal cuantitativo de los textos no parece haber generado, hasta ahora, nuevas interpretaciones capaces de competir con el análisis cualitativo tradicional1. Franco Moretti, junto a Matthew Jockers, es el principal referente de este enfoque2. Moretti señala en una entrevista reciente que el modo de análisis desarrollado por su equipo de trabajo en el Stanford Literary Lab no ha alcanzado todavía una gran precisión, sino que se basa en conectar datos cuantitativos con problemas tradicionales de la narratología y la teoría literaria3. A su vez, reconoce que la acumulación de datos, no solo no resuelve el problema de la interpretación, sino que, al contrario, escenifica la crisis actual de la historia literaria en su dificultad para conceptualizar nuevas preguntas relevantes4.
Aun admitiendo estas limitaciones y problemáticas, la aplicación de la lectura distante ya ha producido algunos resultados dignos de atención. Mediante análisis cuantitativos de una variable concreta en relatos de un género determinado (policial, gótico, etc.), estos investigadores abarcaron un conjunto mucho mayor al definido por el canon y, asimismo, analizaron los motivos por los que una tipología o subgénero particular quedó asentado tal como lo conocemos hoy5. Esto les permitió a Moretti y a sus colaboradores estudiar la evolución de las formas literarias tomando en cuenta una serie de factores, tanto formales como sociológicos. Estos factores intentan explicar los procesos mediante los cuales se constituye el canon de una forma que remite, metafóricamente, a la “selección natural” darwiniana6.
En términos generales, la utilidad de la lectura distante atañe a la posibilidad de analizar un corpus cuya extensión es inabarcable para cualquier ser humano en un plazo razonable de tiempo. Por lo tanto, nos permite focalizarnos sobre unidades más pequeñas o más grandes que el texto (recursos, temas, motivos, tropos, por un lado; y géneros y sistemas, por otro) para obtener una visión más panorámica. En cierta manera, la lectura distante y la denominada “minería de datos” (data-mining) son la versión moderna y computacional de la longue durée de la Escuela de los Anales, cuya influencia es explícitamente reconocida por Moretti (2015)7. Los análisis formales evolutivos diacrónicos y los trabajos geográficos sobre la “literatura mundial” (Weltliteratur), realizados a partir de la teoría económica de los sistemas-mundo, se alimentan del uso de herramientas de las humanidades digitales. Sin embargo, no debemos olvidar que el análisis de la uniformidad y la coincidencia no busca anular la realidad de la diferencia. Se trata de una voluntad de extenderse, experimentalmente, un poco más en el tiempo y el espacio para generar una comprensión más totalizadora. Ilustrado mediante una analogía literaria, podríamos compararlo con un “Aleph” con la potencialidad de ser transmitido.
En este trabajo, nos proponemos trasponer este método de análisis a otro corpus: la investigación en literatura. Con este objetivo, utilizaremos algunas de las herramientas generadas por los estudios de Moretti sobre lectura distante para analizar un corpus conformado por artículos académicos propios del ámbito de los estudios literarios, todos ellos publicados en revistas argentinas vinculadas a universidades entre 2014 y 20158. El propósito de este trabajo es doble: por un lado, realizar un primer acercamiento a un estado actual de los objetos de investigación de la disciplina de los estudios literarios en las revistas académicas de nuestro país y, por otro lado, presentar la utilidad de los trabajos cuantitativos con grandes grupos de textos para trazar mapas posibles de la actualidad de los campos disciplinares.
Corpus
La selección de textos a analizar en este trabajo implicó una búsqueda exhaustiva para lograr un corpus con determinadas características comunes. Con este propósito, descartamos todas las publicaciones que responden a una subdisciplina particular de los estudios literarios, e incluimos en el análisis cuantitativo solamente las secciones de investigación genéricas. Esto implicó excluir los dossiers temáticos cuando eran parte de las publicaciones. Para este primer análisis, nos restringimos a los números publicados en 2014 y 2015 de un total de 12 revistas9. Esto dio como resultado un corpus de 198 artículos, 3431 páginas y 1.559.239 palabras. Sobre ellas empleamos distintas herramientas básicas de conteo de palabras y armado de nubes. Estas son las revistas analizadas:
Anclajes (Universidad Nacional de la Pampa): 30 números [1997-2017]
Badebec (Centro de Estudios de Teoría y Crítica Literaria, Universidad Nacional de Rosario): 10 números [2012-2016]
Cuadernos del Sur (Universidad Nacional del Sur): 45 números [1993-2015]
El taco en la brea (Universidad Nacional del Litoral): 5 números [2014-2017]
Estudios de Teoría Literaria(Universidad Nacional de Mar del Plata): 12 números [2012-2017]
Exlibris (Universidad Nacional de Buenos Aires): 5 números [2012-2016]
Gramma (Universidad del Salvador): 56 números [1989-2016]
Orbis Tertius (Universidad Nacional de la Plata): 25 números [1996-2017]
RECIAL (Universidad Nacional de Córdoba): 11 números [2010-2017]
Revista de Literaturas Modernas (Universidad Nacional de Cuyo): 45 números [1956-2015]
RILL (Universidad Nacional de Tucumán): 21 volúmenes [1996-2016]
Saga (Escuela de Letras, Universidad Nacional de Rosario): 6 números [2014-2016]
Aunque no formaron parte del estudio cuantitativo, creemos importante mencionar cuáles fueron los dossiers incluidos en estas revistas (2014-2015), dado que ofrecen una perspectiva complementaria sobre algunos de los temas más frecuentes entre los especialistas en literatura en nuestro país. Allí se vislumbra cierta intencionalidad por parte de los comités y autoridades, más allá de los proyectos individuales de los autores que envían sus trabajos. En el mismo sentido, un proyecto de investigación propuesto por un individuo o un equipo ante una convocatoria libre se diferencia de un trabajo alentado o guiado por la institución que realiza la propia convocatoria.
Los dossiers pueden dividirse en varios subgrupos. Por un lado, subdisciplinas de los estudios literarios como “Actualidad del hispanismo en argentina”, “Los estados de la teoría”, “Traducción literaria”. Por otro lado, géneros literarios específicos como “El género policial en América Latina y el Caribe (1980-2014)”, “Gótico en América Latina y el Caribe”, “Autoficción”; cruces entre la literatura y problemáticas sociales específicas: “Variaciones de la voz (una muestra de poesía latinoamericana contemporánea)”, “Memorias agrietadas. Cultura y temporalidades”, “Violencia política, memoria y escritura”, “Literatura, cultura y pensamiento de izquierdas en la Argentina del siglo XX”, “Poéticas del margen en la literatura argentina: El régimen de lo visible y lo invisible”, “Género y literatura”. Si bien en los dossiers mencionados se perciben cruces, existen algunos más difíciles de agrupar en categorías restringidas: “Aniversarios: Saer, Pasolini, Bloch, Lukács, Barthes”, “Letrados, hombres de letras e intelectuales en los siglos XVIII y XIX”, “Comunidades y relatos del libro en América Latina”, “La proximidad crítica: hacer hablar a los objetos” y “Figuras del entre: pensamientos y escrituras contemporáneas”.
Probablemente aquellos dossiers que cruzan literatura y problemáticas sociales específicas son los que resultan más ilustrativos de algunas de las tendencias que analizaremos más adelante en este artículo. Como se verá a partir de nuestra lectura distante del corpus, existe una marcada tendencia a plantear explícitamente las conexiones con problemáticas que van más allá del análisis formal/inmanente de los textos literarios en pos de una tematización de conflictos sociales e ideológicos ligados a la memoria y la representación de los cuerpos y las subjetividades disidentes o marginales.
Mediante una aplicación que creamos en Python 3.5 para este propósito, realizamos un mapeo de los espacios de publicación de los trabajos de los investigadores de planta permanente (Adjuntos, Asociados, Principales y Superiores) del área de “Literatura, Lingüística y Semiótica” del Consejo Nacional de Investigaciones Científicas y Técnicas (Conicet) de Argentina10. Al 20 de septiembre de 2017, la actualización de la información brindada por el sitio web oficial registraba 270 investigadores en todo el país, con un total de 7542 publicaciones en revistas periódicas. De ese total de artículos, 174 fueron publicados en la revista Orbis Tertius, indiscutiblemente mayoritaria entre las de nuestro corpus. En una segunda instancia, se destacan Anclajes (63), Cuadernos del Sur (55), Revista de Literaturas Modernas (51), Gramma (43) y Badebec (39). Teniendo en cuenta la cantidad de números en su haber, los casos de Anclajes, Badebec y Orbis Tertius son particularmente llamativos. Luego se observa el caso particular de El taco en la brea que, a pesar de haberse originado recientemente, cuenta con 27 artículos. Por último, y con una cantidad menor, nos encontramos con RECIAL (18), Exlibris (15), Estudios de teoría literaria (12), Saga (11), RILL (8). Estos datos pueden responder a diversas consideraciones por parte de los investigadores a la hora de escoger dónde publicar. Podría tratarse, por ejemplo, de cuestiones de indización y puntaje11, circulación y difusión de las propias revistas, conocimiento de la existencia de los medios y/o facilidades en los envíos.
Metodología
Luego de identificar las revistas y descargar los archivos correspondientes, previa certificación de que tuvieran Reconocimiento Óptico de Caracteres (conocido como “OCR” por sus siglas en inglés), unificamos todos los artículos en un único archivo12. Este archivo fue analizado con distintas herramientas que provee el programa “Voyant Tools” (http://voyant-tools.org/)13. Se trata de una herramienta en línea gratuita (y de código abierto) para analizar y visualizar textos, desarrollada por Stéfan Sinclair (McGill University) y Geoffrey Rockwell (University of Alberta). A diferencia de otros recursos para trabajar en línea con grandes corpus, permite que el usuario incorpore sus propios textos, ya sea copiándolos directamente a un cuadro de texto en el portal del sitio o subiendo archivos (ya sea .txt o .pdf con OCR). Entre las posibilidades que ofrece el sitio, para este trabajo utilizamos:
1. “cirrus”: crea “nubes de palabras” (word clouds). Son representaciones gráficas de un texto en donde el tamaño de cada término se corresponde con la cantidad de apariciones en el corpus (más apariciones equivalen a más tamaño)14;
2. “context”: extrae las palabras inmediatamente anteriores y posteriores a un término elegido y lo sistematiza en un archivo.
Con el texto unificado de la totalidad del material, generamos una nube de palabras de las 3500 páginas de artículos publicados en los últimos años. De esta forma, se puede observar de manera relativa la cantidad de veces que aparecen ciertos términos (con el agregado visual de que el tamaño aumenta conforme la cantidad de veces que aparece). Para lograr una visualización clara, decidimos que las nubes contendrían en total 85 términos. Asimismo, hicimos un filtro de palabras (cerca de 900), o “Stopwords”15, que consideramos irrelevantes para nuestro análisis (como, por ejemplo, “a”, “este” y “alguno”).
Tras generar una primera nube en la que solo filtramos la lista de palabras más generales e irrelevantes para el análisis (ver nota 15), eliminamos sucesivamente los términos que consideramos significativos en cada nivel, lo que resultó en una nueva selección. A su vez, suprimimos las palabras intrascendentes que iban apareciendo por tener una menor cantidad de repeticiones16. De esta manera, cada nivel sucesivo presenta un espectro de términos diversos entre sí, con una frecuencia cada vez menor de repeticiones. Por ejemplo, en el primer nivel se observan palabras que tienen alrededor de 1600 repeticiones; en el cuarto, cerca de 500; y en el décimo, cerca de 225.
A partir de las sucesivas nubes de palabras, y siguiendo estos métodos cuantitativos a lo largo del análisis, fuimos identificando distintas problemáticas, corpus y autores que se iban evidenciando y que hoy son el foco de los trabajos de nuestros colegas. Esto nos permitió, entre otras cosas, estudiar la distribución de palabras alrededor de algunos conceptos claves. Esto implicó, a su vez, la generación de nuevas nubes que reflejaban estos campos semánticos, tal como aparecen en el corpus analizado. En algunas ocasiones, frente a la aparición de un término que refiere a un área de investigación disciplinar (como el nombre de un autor, de un género, de un marco teórico), comparamos los resultados obtenidos con otras posibilidades existentes de las que tenemos conocimiento como investigadores del área. Este es el procedimiento que seguimos, por ejemplo, en la identificación de listas de autores (ya sea en tanto fuentes literarias, o como bibliografía crítica) y de géneros literarios de acuerdo con su frecuencia en el corpus.
Resultados del análisis
La primera nube de palabras, o “Cirrus”, generada por el Voyant Tools, una vez excluidas las Stopwords, fue la siguiente:

Figura n° 1: nivel 1
Muchas de las palabras con mayor frecuencia pertenecen al vocabulario más elemental del análisis de textos literarios (como, por ejemplo: “texto” y “obra”, “crítica” y “escritura”, que se encuentran casi al mismo nivel). Otras, sin embargo, ya exhiben una cierta orientación general que será confirmada por los análisis posteriores: la fuerte presencia de términos que remiten a la relación entre la literatura y su mundo circundante. De ahí, la cantidad de apariciones de los términos “vida” y “mundo”, pero también (aunque a un nivel algo menor) de “cuerpo” y “memoria”. Las nubes de palabras posteriores demostraron ampliamente esta preferencia por temáticas que van más allá del análisis formal17. Un primer vistazo general nos lleva a la observación de que el trabajo investigativo literario actual se inclina más hacia lo sociológico y hacia la relación del individuo con lo social.
La presencia hegemónica del género “novela” en la nube de palabras del primer nivel (donde se visualizan términos que tienen una frecuencia promedio que oscila entre las 1500 y 1800 repeticiones) demuestra que este tipo de textos continúa siendo el objeto privilegiado de los estudios literarios académicos. En función de la aparición de este género, realizamos otras búsquedas que confluyeron en el siguiente gráfico, donde se expresa la relación entre los distintos géneros literarios y otros medios:

Figura n° 2: Géneros literarios y otros medios
El procedimiento aquí consistió, simplemente, en comparar las apariciones de cada una de las palabras listadas en el gráfico (“novela”, “cuento”, etc.). En primera instancia, se observa que los géneros literarios tienen una mayor representación que los otros medios18. Hay que destacar, ante lo que podría esperarse, el caso especial de la crónica, que se ubica en un lugar casi idéntico al de la poesía. Esto puede deberse, tanto a un interés mayor por los géneros vinculados con el periodismo, como –en términos más generales– a la búsqueda de conectar los relatos con experiencias vinculadas al mundo no-literario. A partir de esta observación, nos dirigimos al corpus, ya específicamente, con la intención de corroborar esta impresión. El paso a la lectura cercana nos llevó a una visión más detallada de los contextos de aparición del término. Los más usuales eran: “crónicas policiales”, “crónicas coloniales rioplatenses”, “crónicas españolas medievales y renacentistas”, “crónica política”, “crónicas periodísticas” y “crónica modernista”, entre otros de menor aparición. Si se quisiera afinar aún más el análisis habría que determinar porcentualmente las apariciones en función de la división de artículos, dado que puede darse el caso de que un artículo particular condense una frecuencia muy alta de un término y distorsione el panorama general.
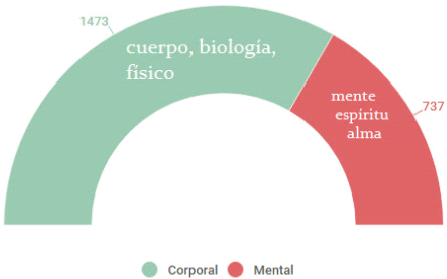
Figura n° 3: Palabras del campo semántico corporal vs. mental
Nuestro análisis continuó con “cuerpo”, que si bien ocupa un lugar relativamente marginal en la distribución de términos en el primer nivel (ubicado a la izquierda en celeste), resultaba claramente visible en el segundo. Cuantitativamente, su presencia es cercana a “política”, “nacional” y “autor”, conceptos con un promedio de 1000 y 1200 apariciones, cuya importancia para los estudios literarios es más evidente. Por el carácter menos previsible de la aparición de “cuerpo” en relación con la investigación literaria decidimos profundizar esta cuestión mediante otras tres herramientas que permiten ahondar en el campo semántico. En primer lugar, seleccionamos algunas palabras ligadas a lo corporal y otras al campo semántico de lo mental/espiritual. Esta confrontación demuestra que hay una clara hegemonía del interés por el cuerpo y de lo concreto por sobre lo más abstracto, algo relativamente llamativo si consideramos que las “letras” están culturalmente más asociadas con el ámbito mental.
En segundo lugar, nos propusimos averiguar en qué sentidos se trabajaba o se mencionaba lo corporal. Para esto combinamos dos herramientas. Por un lado, mediante la herramienta “Context” restringimos nuestro corpus a las palabras que aparecen cercanas a “cuerpo”. Por otro lado, y en base a este nuevo corpus reducido, realizamos una nueva nube de palabras. Ella arrojó los siguientes resultados:

Figura n° 4: Palabras cercanas textualmente a “cuerpo”
Las palabras “goce”, “erótico” y “deseo” parecen remitir a una concepción positiva del cuerpo y de su relación con el entorno. En cambio “monstruo” referiría a una percepción más problemática de la corporalidad. Sin embargo, un análisis de los enunciados concretos en donde aparecen estos términos (nuevamente mediante una lectura cercana) desarma esta oposición. Por ejemplo, el goce aparece cercano a términos como “vergüenza”, “violación”, “náuseas” o “abyección”. Algo similar sucede con el deseo, que en varias ocasiones se manifiesta en el corpus como un elemento en tensión con la civilización y las normativas que impone. La recurrencia de estas vinculaciones semánticas, sumada a nuestro conocimiento previo del área, nos permite suponer la abundancia de trabajos académicos que incorporan debates y perspectivas sobre la corporalidad a partir de la identificación de problemáticas biopolíticas. Este tipo de enfoques, inspirado en gran medida en las figuras de Michel Foucault, Giorgio Agamben y Roberto Esposito (quienes, a su vez, remiten a antecesores como Georges Bataille y Pierre Klossowski) trabaja con una concepción del erotismo como una forma de transgresión. Estas temáticas tienen también una representación cada vez mayor en los encuentros académicos del área19, como lo demuestran por ejemplo las jornadas de reflexión “Monstruos y Monstruosidades” (que ya cuenta con cinco ediciones) y el encuentro “Cuerpo y violencia en la literatura y las artes visuales” (2017).
De nuevo en nuestro análisis general, una tercera selección sobre el corpus dio como resultado la siguiente nube de palabras (figura 5). Aquí aún se observa una cantidad de términos genéricos y relativamente esperables (“sociedad”, “escritor”, “sujeto”). Por otra parte, para nuestro ámbito profesional, un término como “género”, que se destaca en esta figura, remite tanto a lo discursivo-literario como a los debates propios de las teorías sobre género y sexualidad. Una lectura cercana de estos términos permite comprobar que aparece con similar frecuencia en ambas acepciones.

Figura n° 5: nivel 3
Aquí también encontramos la primera aparición de un autor literario. A partir de la visualización de “Borges” en este tercer momento (junto con palabras de 700 menciones promedio) nos propusimos concentrarnos en los nombres propios para observar qué autores argentinos del siglo XX eran citados y mencionados con mayor frecuencia. El análisis produjo los siguientes resultados:

Figura n° 6: autores argentinos más mencionados
La recurrencia de Borges duplica la del resto20. Es posible hipotetizar, no obstante, que un gran número de estas menciones no están vinculadas con análisis específicos de sus obras, sino con citas y alusiones ocasionales. La significativa presencia de Rodolfo Walsh parece remitir al mismo campo de algunos términos que, ya hemos visto, se vinculan con los problemas relacionados con la memoria y la política argentina de las últimas décadas. A su vez, la obra de Walsh, atravesada por algunos de los conflictos sociopolíticos más relevantes de la historia argentina reciente, es, a menudo, utilizada como una forma privilegiada para pensar problemáticas del presente inmediato.
Los sucesivos niveles de “Cirrus” analizados derivaron en cuadros con la siguiente cantidad de repeticiones promedio de palabras y los correspondientes ejemplos:
4º (500): “casa”, “identidad”, “protagonista”, “país”;
5º (400): “mujeres”, “sistema”, “México”, “viaje”;
6º (375): “dios”, “revolución”, “juego”, “deseo”, “guerra”;
7º (325): “traducción”, “estética”, “ensayo”, “origen”, “naturaleza”;
8º (300): “animal”, “pueblo”, “tierra”, “límites”, “popular”, “madre”, “padre”;
9º (275): “Benjamin”, “joven”;
10º (225): “estructura”, “imaginario”.
A continuación, se pueden observar, a modo ilustrativo, los niveles 6° y 9°21.

Figura n° 7: nivel 6

Figura n° 8: nivel 9
Ya a partir del nivel 9 se puede encontrar el nombre de Walter Benjamin, que luego aparece en un lugar más protagónico en el nivel 10. Su presencia desembocó en la búsqueda de otros teóricos, lo que llevó a la elaboración de la siguiente lista (figura 9). Aquí se ofrece un panorama de la teoría literaria que se lee (o, mejor dicho, que se menciona, cita y aplica en los análisis) en la actualidad, al menos en nuestro país:

Figura n° 9: teóricos más mencionados
Walter Benjamin y Giorgio Agamben son dos autores esperables en un contexto donde los estudios sobre la memoria, el cuerpo y la experiencia tienen un enorme peso. Agamben, junto con Jean-Luc Nancy, Jacques Rancière y Judith Butler, pertenece al limitado subgrupo de teóricos vivos dentro de la lista. Ninguno de ellos pone el acento en el análisis inmanente de los objetos literarios. Roland Barthes y Michel Foucault, por otro lado, continúan siendo referencias frecuentes y no han sido desplazados por otras figuras más recientes. Los teóricos argentinos más mencionados son Beatriz Sarlo (141), David Viñas (126), Josefina Ludmer (97) y Noé Jitrik (96).
Fuera de la paridad que se observa en la crítica argentina, la evidente hegemonía de autores de sexo masculino nos llevó a preguntarnos por la frecuencia de palabras vinculadas a la profesión que remitieran a la identificación de géneros femenino y masculino. Para ello, analizamos aquí la aparición de los términos “autor”, “autora”, “escritor” y “escritora”. Si bien este método tiene algunas limitaciones, y hay diversos factores que podrían incidir sobre los resultados (por ejemplo: podría darse el caso de que las autoras fueran referidas por su nombre más a menudo que los autores; tampoco analizamos los plurales “autores” y “autoras” porque el primero podría incluir a autoras), el siguiente gráfico exhibe una contundente primacía de escritores masculinos22.

Figura n° 10: autor / escritor vs. autora / escritora
Sin embargo, esta diferencia se invierte en la presencia de los términos “masculino” (110 apariciones en el corpus) y “femenino” (278 apariciones).

Figura n° 11: “Femenino” vs. “Masculino”
La primera observación que surge al respecto es que el interés por las cuestiones de género y el estudio de la construcción y representación social de lo “femenino” no implicó, al menos en una primera etapa, un viraje hacia el análisis de obras escritas por mujeres. Por supuesto, esto no puede comprobarse únicamente a partir de los gráficos mostrados y exigiría un estudio que incluya componentes cualitativos. No obstante, para afinar el análisis cuantitativo, podría cruzarse este dato con la cantidad de nombres propios de autores que aparecen a lo largo de los artículos.
Podría llevarse a cabo una comparación de la proporción de autoras y autores de los artículos que nosotros utilizamos para nuestro trabajo (es decir, de quienes publicaron entre 2014 y 2015 en las revistas académicas de nuestro corpus) para luego cruzar este dato con la cantidad de estudiosos citados en las bibliografías (que, en la mayoría de los casos, son investigadores/as consagrados/as por el campo disciplinar).
Otro análisis posible consistiría en dividir el corpus en dos (artículos de autores y artículos de autoras) para volver a analizar si persiste la relación entre los términos que graficamos en las figuras 9 y 10. Si bien aquí no nos detendremos en detalle en esto, por una cuestión de extensión, sería interesante ampliar este tipo de análisis, dado que permitiría desarticular o confirmar preconceptos y evidenciar ciertos movimientos del campo intelectual literario contemporáneo.
Por último, y como ejemplo ulterior de las posibilidades que abre este enfoque metodológico, nos propusimos buscar algunas palabras ligadas a los marcos teóricos más empleados en los estudios literarios en las últimas décadas. Esto nos permitió obtener el siguiente cuadro, en el que además de la frecuencia de los términos centrales se observan, entre paréntesis, algunos de los otros términos con los que suelen compartir contextos en el corpus.

Figura n° 12: algunos términos teóricos relevantes y palabras asociadas
Resulta muy complejo asignar el concepto de “discurso” a un enfoque teórico específico, ya que es una palabra que se utiliza en sentidos diferentes. Por ejemplo, tanto Mijail Bajtín como Foucault y Teun van Dijk plantean al discurso como objeto de análisis, pero lo hacen desde perspectivas diversas. A su vez, el sintagma “discurso político” puede simplemente referir a los discursos en el sentido más cotidiano del término23.
El segundo término más usado, “experiencia”, remite con mayor facilidad a un conjunto de reflexiones a menudo relacionadas con la obra de Walter Benjamin. Los términos que aparecen asociados confirman que es uno de los conceptos más empleados para conectar a la literatura con la vida. “Campo”, “sistema” y “estructura” son conceptos que pueden emplearse, tanto para el análisis inmanente, como para referirse de manera más general al posicionamiento de un autor o texto en una serie más amplia.
Conclusiones
A modo de síntesis, consideramos importante destacar una serie de observaciones generales que surgen de esta primera aproximación cuantitativa. En primer término, advertimos una tendencia a privilegiar el eje literatura-realidad o literatura-vida (inevitable en temáticas como “memoria”, “experiencia” o “política”) por sobre los análisis que apuntan hacia los procedimientos literarios como objetos de investigación. En segundo lugar, las novelas argentinas (y, en particular, aquellas escritas por autores de género masculino) ocupan un lugar central en el corpus de análisis y son, por amplia diferencia, el género más estudiado24. En tercera instancia, la presencia masiva de algunas palabras ligadas a la corporalidad y, en particular (aunque esto es más difícil de cuantificar de forma objetiva), hacia corporalidades “disidentes” (o contra-hegemónicas) sugiere una tendencia a repudiar las abstracciones clásicas del análisis de las “bellas letras”25. En cuarto lugar, hay una clara preferencia por teóricos que exploran otros campos aparte del literario (biopolítica, análisis de la experiencia, micropoder), tales como Walter Benjamin, Giorgio Agamben y Michel Foucault. Aunque hemos visto que figuras como Sarlo o Viñas son frecuentemente invocadas, existe una preeminencia de autores internacionales para encarar cuestiones teóricas. Por último, es necesario considerar que la amplitud de problemas que suscita el trabajo con terminología propia del análisis literario podría evidenciar cierta carencia conceptual específica de la disciplina. En otras palabras, la hegemonía de temáticas como las que hemos descripto tiende a evidenciar, creemos, un esfuerzo por ampliar los límites de lo literario, antes que por precisar su especificidad formal y las herramientas con las que puede ser caracterizada.
Es probable que dentro de unos años la mayoría de los artículos que analizamos en nuestro corpus pasen al olvido. Eso no quiere decir que carezcan de pertinencia o calidad académica. La repercusión de un artículo académico depende, en gran medida, de la figura de autor, la visibilidad y repercusión de una revista (o de un número en particular), y muchas otras cuestiones relativamente azarosas. Por todo esto creemos que un estudio de este tipo permite un panorama más general que resulta útil para ver las inquietudes políticas, culturales y sociológicas en un contexto determinado26.
Resta decir que, para tener un espectro más completo y una visión de conjunto más acabada de la investigación en literatura de las instituciones universitarias en el presente, podría ampliarse el corpus de análisis hacia actas de congresos, libros publicados por universidades, tesis en repositorios (de grado y posgrado) y títulos de proyectos. Por otra parte, y como señalamos en las críticas que ha recibido este tipo de enfoque, somos conscientes de que debe complementarse con un análisis que apunte a una historización más precisa de los distintos aspectos que intervienen en la producción y recepción de los textos. A su vez, teniendo en cuenta el lugar que ocupa en nuestra disciplina el trabajo interpretativo, vale destacar también que esta clase de análisis resulta inevitablemente reduccionista, ya que transforma razonamientos e hipótesis en conjuntos de términos cuantificables. Pese a estas limitaciones, esperamos que este primer paso despierte la inquietud y resulte provechoso para quienes quieran detenerse en algún aspecto, concepto o autor en especial y puedan, sin duda, realizar un trabajo más relevante para sus respectivas sub-disciplinas.
Notas
1 Esto lo señalan incluso quienes comparten una mirada positiva sobre las propuestas de lectura distante: “Even so, my guess is that, while many critics will admire Moretti, relatively few will follow him. The technical skills are learnable; English majors can take computer-science courses. But the sacrifices, intellectually and, as it were, artistically, are too great” (Joshua 2014). Otro cuestionamiento frecuente proviene del uso excesivo y/o superficial de gráficos y recursos visuales como estrategia principal de análisis. Según el mismo Moretti, no se ha llegado actualmente a producir gráficos que posibiliten un análisis igual de rico y denso que el que proveen las interpretaciones tradicionales, ya que se privilegia excesivamente su mera acumulación (Hackler y Kirsten 2016).
2 En “On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges” (Jänicke et al. 2015) se realiza un recorrido sucinto por los aportes de las humanidades digitales en los últimos años y se coloca el foco en las especificidades de las lecturas cercana y distante. Específicamente, de Jockers, codirector conjuntamente con Moretti del Stanford Literary Lab entre 2010 y 2012, resulta fundamental la lectura de Macroanalysis: digital methods and literary history (2013). Puede encontrarse una breve historización del desarrollo de la metodología de estas corrientes en el texto de Oberhelman (2015).
3 “So far, we’ve not developed a repeatable methodology. The only thing that tends to repeat itself is the attempt to connect or reconnect the quantitative findings with already existing aspects of literary theory-narrative, stylistic”, afirma Moretti en respuesta a la pregunta sobre la utilización de archivos digitales (Hackler y Kirsten 2016).
4 “The great advantage of quantification is that all of a sudden millions of texts that had, for all practical purposes, disappeared, become available for research. But you have to have a good question to ask these archives. A text always speaks to us; an archive doesn’t. Everything is there, but do we have good research questions? I would say no. The reason is not the fault of people who work in the digital humanities. It’s the fault of literary history. In the last 30 or 40 years it has been a very uninteresting discipline. It has not generated many interesting debates-whether of method or of substance. This is the situation in which we are suddenly confronted with millions of books and we are not sure anymore what we are interested in” (Hackler y Kirsten 2016). Aunque no entraremos en detalle, esta perspectiva ha recibido críticas ya sea desde la defensa de la lectura interpretativa clásica, como desde quienes objetan las pretensiones de cientificidad de su trabajo El mismo Moretti reconoce la crítica de Jerome David en “Más conjeturas” (2015). Katherine Bode (2017) cuestiona a Moretti y Jockers ya que ambos no consideran el valor crítico e interpretativo de los enfoques bibliográficos y editoriales que median nuestra relación con las obras literarias. Al considerar los textos como datos abstractos, caen en una perspectiva ahistórica peligrosamente cercana a la del New Criticism.
5 Entre los numerosos ejemplos de este tipo de análisis que ofrece la obra de Moretti, podemos mencionar su estudio del policial titulado “El matadero de la literatura” donde, a partir de la presencia o ausencia de indicios, y según su subclasificación en un esquema arborescente (de acuerdo con su necesidad, visibilidad y posibilidad de ser decodificados), explica cómo se determinó la conformación del canon genérico (Moretti 2015). “In Moretti’s evolutionary model for thinking about the novel, forms bifurcate. The tree of literature is constantly sprouting new branches, but some die off, taking their place in the fossil record of “‘the great unread’. The readers have spoken” (McKenzie Wark 2013).
6 Para más información, ver Moretti “On Literary Evolution” en Signs Taken for Wonders (1983) y el capítulo “Trees” de Graphs, Maps, Trees (2005).
7 Se denomina “minería de datos” al proceso estadístico de identificación de patrones, en grandes conjuntos de información, por medio de la utilización de herramientas informáticas. Este tipo de proceso es utilizado a menudo en los ámbitos comerciales y político-económico para diseñar campañas publicitarias y propagandísticas en base al relevamiento de enormes cantidades de información (big data) de los usuarios de las diferentes plataformas digitales. La expresión “minería de textos” (text-mining) se emplea para referirse a este tipo de trabajo cuando el corpus analizando está constituido por textos.
8 El antecedente más directo de este trabajo es un breve artículo publicado por Mariano Vilar (2015) en la revista Luthor que tiene como objeto un conjunto de ponencias del Congreso Internacional de Letras.
9 En la lista que incluimos a continuación se excluye la información posterior a la presentación de una primera versión, más acotada, del trabajo en el I Congreso Internacional de Humanidades Digitales. Construcciones locales en contextos globales de 2016. En la mayoría de los casos (pero no en todos, y por eso mantenemos la restricción temporal), en el transcurso de estos meses, ha salido un nuevo número. En otro orden, cabe aclarar que la publicación Letras de la Universidad Católica Argentina (que cuenta con 70 números publicados entre 1981 y 2014) no fue utilizada para el análisis debido a que digitalmente solo cuenta con los índices.
10 Para el desarrollo de esta aplicación utilizamos la biblioteca “BeautifulSoup”, que permite incorporar funciones de web-scrapping al entorno de Python.
11 En relación con la indización es interesante la declaración, firmada por muchas revistas, que se publicó en el séptimo número de RECIAL en 2015 (ver aquí). Por otra parte, y sobre las criterios específicos del Conicet, para los puntajes no se puede soslayar la resolución de “Bases para la Categorizacioìn de Publicaciones Perioìdicas en Ciencias Sociales y Humanidades” de 2014 (ver aquí).
12 Los programas que se utilizan para llevar a cabo el OCR (ya sea a partir de la digitalización de documentos en papel o de documentos digitalizados) transforman una imagen en cadenas de caracteres que habilitan la búsqueda de términos en los textos.
En nuestro caso, en primer lugar, realizamos la experiencia de análisis de manera independiente sobre el corpus de cada año (2014 y 2015). Luego, comparando los resultados, observamos que las distinciones no eran relevantes y que, en cambio, era mucho más rico el análisis conjunto. En el futuro, creemos que podría resultar productivo contrastar los resultados con corpus similares en intervalos de tiempo mayores.
13 En una primera etapa, intentamos utilizar también el sitio “ContaWords” (http://contawords.iula.upf.edu), pero nos encontramos con fallas en su funcionamiento que impidieron obtener resultados satisfactorios.
14 Aquí hay que tener en cuenta que tanto la ubicación como el color que se le otorga a la palabra no tienen ninguna implicancia en el análisis y se dan de manera azarosa. Otra dificultad que presenta la herramienta, cuando es utilizada de manera independiente, es la polisemia.
15 Estas son las stop-words que fueron anuladas en todo el corpus: 1, 1851, 1853, 2, 2014, 2015, 3, 4, 5, 7, 8, 9, 9580, a, además, aires, al, algo, algún, alguna, algunas, alguno, algunos, allí, ambos, and, ante, antes, aquel, aquellas, aquellos, aquí, arriba, así, atrás, aunque, Badebec, bajo, bastante, bien, buenos, cada, caso, cierta, ciertas, ciertos, como, cómo, con, conseguimos, conseguir, consigo, consigue, consiguen, consigues, cual, cuando, da, de, del, dentro, desde, después, di, donde, dos, durante, e, el, él, ella, ellas, ellos, embargo, empleáis, empleamos, emplean, emplear, empleas, empleo, en, encima, entonces, entre, era, éramos, eran, eras, eres, es, esa, ese, eso, esta, está, estaba, estado, estáis, estamos, están, estas, este, esto, estos, estoy, fin, fue, fueron, fui, fuimos, ha, hace, hacéis, hacemos, hacen, hacer, haces, hacia, hago, han, hasta, hay, in, incluso, intenta, intentáis, intentamos, intentan, intentar, intentas, intento, ir, issn, juan, la, largo, las, le, literatura, lo, los, manera, maneras, maría, más, me, mi, mientras, mío, misma, mismo, modo, muchos, muy, n, ni, ni, no, nº, nos, nosotros, o, of, otra, otras, otro, otros, p, para, pero, podeis, podemos, poder, podría, podríais, podríamos, podrían, podrías, por, por qué, porque, pp, primero desde, puede, pueden, puedo, que, qué, quien, sabe, sabéis, sabemos, saben, saber, sabes, se, sea, según, septiembre, ser, si, sí, sido, siendo, sin, sino, sobre, sois, solamente, solo, sólo, somos, son, soy, su, sus, tal, también, tan, tanto, tenéis, tenemos, tener, tengo, the, tiempo, tiene, tienen, to, toda, todas, todo, todos, trabaja, trabajáis, trabajamos, trabajan, trabajar, trabajas, trabajo, tras, trata, través, tuyo, último, un, una, unas, uno, unos, usa, usáis, usamos, usan, usar, usas, uso, va, vais, valor, vamos, van, vaya, veces, verdad, verdadera, verdadero, vez, vol, vosotras, vosotros, voy, y, ya, yo.
16 Estas son las stop-words de cada recorte sucesivo:
2° recorte: 10, 12, 19, 2000, 2001, 2003, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2013, 44, 45, 6, Ana, año, años, argentina, centro, crítica, debe, decir, dice, discurso, ejemplo, ello, escritura, espacio, et, fi, forma, formas, frente, gran, había, historia, i, Il, il, imágenes, José, lado, lectura, libros, luego, lugar, m, marzo, menos, mundo, novela, nueva, obra, parece, parte, partir, personajes, podría, posible, primer, primera, primero, propia, propia, propio, pues, punto, relación, s, sentido, siempre, siglo, texto, textos, tres, ver, vida, xx.
3° recorte: 11, 13, 1668, 20, 2004, 2012, 40, 7426, 7811, ahora, arte, as, aún, autor, casi, ciudad, contra, cosas, cuerpo, cultura, cultural, edición, esos, están, estudios, exlibris, experiencia, experiencia, he, hecho, hombre, imagen, is, j, julio, lector, lector, lengua, lenguaje, les, letras, libro, literaria, literarias, literario, literarios, mayor, mediante, memoria, momento, mucho, muerte, mujer, nacional, nuestra, obras, orbis, palabras, pasado, permite, personaje, poema, poesía, política, político, presente, primera, realidad, relato, relato, respecto, revista, señala, social, sociales, te, teoría, tertius, that, universidad, xix.
4° recorte: 14, 15, 1998, 2002, 22, 41, 55, afirma, allá, amor, Antonio, aparece, autores, Borges, campo, che, crónica, cuenta, cuenta, dar, deja, diciembre, ed, elementos, encuentra, época, escritor, escritores, figura, final, fuera, género, Gómez, haber, hombres, http, idea, lectores, Madrid, Manuel, medio, mejor, mirada, modos, nada, narrador, narrativa, nombre, nuestro, nuevo, nunca, palabra, poco, poética, posibilidad, presenta, proceso, relaciones, resulta, segunda, será, sociedad, sujeto, this, torno, tradición, v, violencia, volumen, voz.
5° recorte: 16, 1996, 1997, 53, acerca, América, análisis, aquello, artículo, carácter, casa, cierto, cine, comunidad, construcción, cosa, cuentos, cuerpos, cuya, Darío, des, diferentes, editorial, esas, escribir, estar, ficción, general, habla, identidad, investigación, investigaciones, línea, Luis, nación, nro, nuevos, objeto, Olivari, on, orden, páginas, país, pensamiento, pensar, perspectiva, pone, principio, producción, protagonista, r, real, relatos, representación, segundo, sur, t, términos, última, último, veces, vuelve.
6° recorte: Barcelona, cambio, común, cualquier, cualquiera, escena, hablar, leer, México, mujeres, novelas, poeta, propone, proyecto, público, serie, tipo, viaje.
7° recorte: 17, 1999, argentino, clave, concepto, contexto, crítico, cuento, deseo, diferencia, efecto, España, estudio, garcia, García, grupo, guerra, juego, Martínez, medida, modelo, movimiento, narración, número, particular, poemas, presencia, quienes, sería, sistema, teórico, vista.
8° recorte:, 1, 18, 1994, 1995, 21, acción, ahí, asimismo, aspectos, busca, by, características, Carlos, casos, Cedintel, constituye, construye, crónicas, cuales, cuanto, cuestión, culturales, cuyo, dado, década, departamento, desarrollo, día, diario, dicho, dios, discursos, diversas, diversos, do, ediciones, ensayo, escribe, espacios, estética, etc, falta, Fernández, fhuc, filol, función, futuro, gramma, grandes, hemos, histórica, histórico, igual, importancia, invest, it, Jorge, junto, l, latinoamericana, lecturas, lenguas, lleva, Martín, muchas, muestra, naturaleza, necesidad, nuevas, origen, período, pesar, plata, políticas, prácticas, precisamente, publicación, puesto, queda, quiere, razón, revolución, siguiente, silencio, sostiene, tema, término, título, traducción, unl, ve.
9° recorte: 1989, 27, 31, acto, adelante, ámbito, ángel, animal, aparecen, aquella, Beatriz, belleza, búsqueda, central, ciencia, concepción, condición, corpus, cuadernos, educación, ef, encuentro, español, especialmente, existencia, expresión, facultad, filosofía, finalmente, fondo, for, hechos, his, hoy, humano, ideas, ii, implica, importante, intelectual, interés, límites, luz, madre, marco, material, materiales, mis, modernidad, necesario, new, original, padre, paso, persona, personas, popular, posición, práctica, pregunta, problema, produce, propósito, propuesta, rasgos, refiere, resumen, rodríguez, san, situación, teatro, tierra, todavía, varios, visión, with.
10° recorte: 1990, 1992, 23, 2314, 25, 30, 3894, 4669, ambas, anterior, aspecto, Benjamin, bibliografía, camino, clase, conjunto, conocimiento, contrario, d, descripción, distancia, doble, don, ensayos, escrito, escritura, Eva, existe, existencia, finalmente, fuerza, géneros, gobierno, historias, joven, latina, lógica, lucha, mal, martí, mí, mismos, momentos, moral, noche, noción, notas, objetivo, objetos, ojos, papel, per, personal, primeros, publicado, pueblo, referencia, santa, tenía, versión, voces, Walsh, xviii.
17 A lo largo del trabajo, y a modo de ejemplificación, presentaremos algunas de las nubes analizadas. No obstante, la totalidad de los “Cirrus”, y otras vetas del estudio, pueden observarse en el Prezi (enlazado AQUÍ) que acompañó la exposición de la primera versión de la investigación en el Congreso mencionado en la nota 9.
18 Aquí se puede observar una de las limitaciones que encontramos en este análisis. Hubiéramos deseado incluir las “series” televisivas, pero resultaba dificultoso por la polisemia del término.
19 Pudimos comprobar, además, que en los programas de determinados eventos académicos de Letras de los últimos años el término “cuerpo” aparece cada vez con más frecuencia en los títulos de las ponencias. Véase el Prezi, donde figura el gráfico que lo ilustra.
20 Entre los autores del siglo XIX o principios del XX, encontramos una preeminencia por parte de Domingo F. Sarmiento y Leopoldo Lugones.
21 P Para la visualización completa, volvemos a remitir al Prezi mencionado en la nota 19.
22 Es importante señalar que no se trata de la distribución de autoras y autores de los trabajos académicos analizados, sino de la mención de la palabra “autor” o “escritor” comparada con “autora” o “escritora” a lo largo del corpus.
23 Durante el proceso de elaboración de este trabajo comparamos las nubes de palabras que se producen con dos clásicos de la crítica del siglo XX: Anatomy of Criticism de Northrop Frye, y Mimesis de Erich Auerbach. Si bien encontramos varios términos en común, las diferencias surgían en el uso de conceptos como “héroe” (que era fundamental para Frye y otros críticos de su generación, pero que está hoy por hoy, casi abandonado) y “estilo” (categoría fundamental para Auerbach que ya no tiene gran peso en el estudio de la literatura, al menos en comparación con otras cuestiones).
24 Desde el punto de vista formal, en el discurrir temporal es donde se perciben los cambios (en nuestro caso, de objetos y métodos investigativos). En relación con el análisis cuantitativo, en “Estilo, S.A.” (2015), Moretti sostiene: “el foco en los extremos omite un aspecto crucial del trabajo cuantitativo: lo principal no son los pocos cambios drásticos y rápidos, sino los numerosos cambios pequeños y lentos” (218). Unas cuantas páginas antes, en el ensayo que abre el libro, reflexiona: “Las transformaciones más significativas no ocurren porque una forma disponga de mucho tiempo, sino porque en el momento justo –que por regla general es muy breve– dispone de mucho espacio” (24). Esto último repercute de manera importante en un análisis como el realizado aquí, en la medida en que abarca distintas regiones del país.
25 Esta tendencia puede manifestarse en varios niveles: ya sea en contra de la “interpretación” y la hermenéutica como forma privilegiada de desentrañar un sentido histórico (o biográfico en un texto), en contra de la separación de un plano formal/estilístico del contexto en el que una obra es producida, o, en términos más generales, por contraposición a cierto humanismo asociado con la literatura como transmisora de valores morales burgueses.
26 En una tónica similar, Moretti analizaba la conformación del canon. Hines lo explica de la siguiente forma: “Formal techniques such as free indirect discourse, or possible structures in detective fiction, evolve for Moretti within cultural, social, and market systems through principles of divergence and selection. The advantage of envisioning literary development in terms of Darwinian trees is, as Moretti points out, restoring to visibility the ‘lost 99% of the archive’ that is ignored when scholars give exclusive focus to the ‘winners’ in the struggle for critical and popular attention” (Hines 2010: 23).
Referencias bibliográficas
1. Bode, Katherine. “The Equivalence of «Close» and «Distant» Reading; or, Toward a New Object for Data-Rich Literary History”, Modern Language Quarterly, vol. 78, n.° 1, 2017, pp. 77-106, Doi 10.1215/00267929-3699787.
2. Hackler, Ruben y Guido Kirsten. “Distant Reading, Computational Criticism, and Social Critique: An Interview with Franco Moretti”, Foucault Blog, Universität Zürich, 16 de Mayo 2016, http://www.fsw.uzh.ch/foucaultblog/featured/144/distant-reading-interview-with-franco-moretti.
3. Hines, Chad Allen. “Evolutionary Landscapes: Adaptation, Selection and Mutation in 19th Century Literary Ecologies”. Tesis Doctoral, Universidad de Iowa, 2010, http://ir.uiowa.edu/cgi/viewcontent.cgi?article=1699&context=etd.
4. Jänicke, Stefan, et al. On close and distant reading in digital humanities: A survey and future challenges, Cagliari, EuroVis, 2015. [ Links ]
5. Jockers, Matthew. Macroanalysis: digital methods and literary history, Urbana, University of Illinois Press, 2013. [ Links ]
6. McKenzie Wark, Kenneth. “The Engine Room of Literature: On Franco Moretti”, Los Angeles Review of Books, Los Ángeles, 5 de Junio 2013, https://lareviewofbooks.org/article/the-engine-room-of-literature-on-franco-moretti/.
7. Moretti, Franco. Lectura distante, Buenos Aires, Fondo de Cultura Económica, 2015. [ Links ]
8. Moretti, Franco. Graphs, Maps, Trees, Nueva York, Verso. 2005. [ Links ]
9. Moretti, Franco. Signs taken for Wonders, Nueva York, Verso. 1983. [ Links ]
10. Oberhelman, David. “Distant Reading, Computational Stylistics and Corpus Linguistics: the Critical Theory of Digital Humanities for Literature Subject Librarians”, Digital Humanities in the Library, Association of College and Research Libraries, a division of the American Library Association, 2015, pp. 53-66.
11. Vilar, Mariano. “Estrategias y nubes de palabras. Una lectura superficial de la producción académica en Letras”, Revista Luthor, vol. VI, n.° 23, 2015, pp.1-14.
Fecha de recepción: 19/10/2017
Fecha de aceptación: 27/08/2018.