Serviços Personalizados
Journal

Artigo
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkSaberEs
versão impressa ISSN 1852-4418versão On-line ISSN 1852-4222
SaberEs vol.11 no.2 Rosario dez. 2019
ARTÍCULOS
Imputación de datos faltantes del censo de población y vivienda de Uruguay utilizando técnicas de estadística espacial1
Missing data imputation using spatial statistics techniques applied to Uruguay census of population and housing
María Eugenia Riaño*
* Universidad de la República (UdelaR), Uruguay.
Contacto: eugenia@iesta.edu.uy
Resumen. En general, la calidad y cobertura del Censo de Población y Vivienda de Uruguay del año 2011 fue calificada como positiva. Sin embargo, su implementación no estuvo exenta de inconvenientes. La omisión se concentró en zonas socioeconómicamente más vulnerables, lo que afectaría el mecanismo utilizado por el gobierno para seleccionar la población beneficiaria de programas de transferencias monetarias. El patrón de la población elegible y de la propia omisión hace necesaria una regionalización previa a la imputación, dada la distribución espacial heterogénea en el mapa de la variable de interés. Las regiones se construyen mediante el algoritmo de árboles oblicuos de decisión. Se ajustan modelos autorregresivos espaciales en cada región que son evaluados utilizando validación cruzada, y se comparan los resultados con el de un modelo global. Los modelos con menor error dentro de cada región muestran un rezago similar medido en distancia, a excepción de un caso. El modelo global presenta un error del mismo orden que los modelos locales, pero presenta autocorrelación espacial en los residuos, por lo que se decide trabajar con los modelos obtenidos por región. Los resultados de la imputación muestran una subestimación de la población elegible de un 5% sobre el total estimado con datos censales.
Palabras Clave: Árboles de decisión; Modelos SAR autorregresivos; Validación cruzada.
Abstract. Uruguay National Census was quality and coverage positively evaluated in general, attaining international standard requirements. However, the data collecting process had some difficulties. The omission are concentrated in segments socioeconomically vulnerable. This could have an impact over the algorithm performed by the government to select the beneficiary population of cash-transfer programs. The heterogeneous spatial pattern of the target population and of the omission itself makes necessary define regions for the imputation of the missing data. Regions are obtained by means of spatial oblique decision trees. Spatial Autorregresive models are adjusted for each region. The models are assessed using cross-validation methods. Results are compared with the performance of a global model for the whole map. Except by one region, models that minimize cross-validation's errors show a similar lag in each region. The cross-validation error for the global model is quite similar. Nevertheless, spatial autocorrelation is detected according to the Moran test for residuals. Hence, the data imputation is performed by regions, with local SAR models, selecting the lag according to the cross-validation error. Results show that target population is underestimated approximately by a 5% over the total obtained with census data.
Keywords: Classification and Regression trees, Cross-validation, SAR models.
Original recibido el 04/04/2018
Aceptado para su publicación el 11/02/2019
1. Introducción
En general, la calidad y cobertura del Censo de Población y Vivienda (Censo) realizado en Uruguay en el año 2011 fue calificada como positiva, cumpliendo con los estándares exigidos internacionalmente. Sin embargo, su implementación no estuvo exenta de inconvenientes. No se cuenta con información de determinados hogares cuyo domicilio fue relevado, y para algunos se cuenta con sólo información parcial relativa a la composición del hogar.
La omisión censal se concentra en zonas socioeconómicamente vulnerables. Esto afectaría la construcción del mecanismo utilizado por el Ministerio de Desarrollo Social del Uruguay (MIDES) para seleccionar a la población beneficiaria de los programas de transferencia monetaria. Este mecanismo se basa en la Encuesta Continua de Hogares (ECH) cuyo marco muestral es el del Censo, y refleja los problemas de omisión.
En el presente trabajo se presentan los resultados obtenidos para la imputación de población elegible del programa Tarjeta Uruguay Social (TUS) en las zonas omisas del Censo. El marco geográfico es el del departamento de Montevideo. Se observa que el patrón espacial de la omisión es diferente por zonas, por lo que se hace necesario definir regiones de imputación.
En las siguientes secciones se presenta la descripción del problema, el marco teórico y la metodología a utilizar. Se presentan los resultados obtenidos y finalmente se realiza una discusión en donde se plantean las direcciones futuras de trabajo dentro del marco de esta investigación.
1. 1. Descripción del problema
En el año 2008, a pedido del MIDES, la Universidad de la República construye un índice denominado Índice de Carencias Críticas (ICC), con el fin de definir inicialmente la población elegible del programa de Asignaciones Familiares del Plan de Equidad. Luego también es utilizado para definir la población elegible de los programas de transferencias Tarjeta Uruguay Social (Ministerio de Desarrollo Social, 2013).
El ICC es un modelo probit que predice la probabilidad de que un hogar pertenezca al primer quintil de ingresos, en base a variables que reflejan su situación en términos de educación, vivienda, confort y composición del hogar. Junto con la estimación del ICC, se determina también un punto de corte por región (Montevideo - Interior) que permite distinguir entre los hogares que según la predicción del modelo pertenecen a la población elegible, y los que no. Es decir, se fija un valor del ICC a partir del cual un hogar sería población elegible para el programa por región.
Dichos umbrales se fijan de modo de permitir la elegibilidad de la cantidad de hogares que la Ley define deben recibir el beneficio, tomando como referencia la ECH que se considera representativa del total poblacional.
Para fijar los umbrales, se estima el ICC para los hogares de la ECH y se calcula la probabilidad de pertenecer al primer quintil de ingresos. Luego se ordenan en forma decreciente según la probabilidad calculada por el modelo, y dada la cantidad de hogares que pretende alcanzar el programa se estima la distribución de los mismos entre Montevideo - Interior. Se realiza una suma acumulada de los pesos muestrales
que permite identificar cuáles son los hogares de la muestra que representarían a los beneficiarios del programa y luego tomando esos hogares se estima la proporción Montevideo - Interior.
Una vez determinada la cantidad de posibles beneficiarios del programa por región, el umbral del ICC se fija en el lugar donde (ordenado en forma decreciente) la estimación de la población beneficiaria se iguale a la cantidad de beneficiarios que pretende alcanzar el programa.
Dado que el marco de la ECH es el del Censo 2011, cuya omisión se concentra en zonas socioeconómicamente vulnerables, se cuestiona cual sería el efecto de la omisión en los umbrales del ICC. Es decir, si los hogares que no se incluyen en la ECH por no estar en el marco son más vulnerables que los demás, los umbrales se verían modificados al alza. La omisión del censo tendría como consecuencia que la distribución de los programas entre los hogares beneficiarios no fuera la correcta, así como también podría verse modificada la distribución de las partidas de beneficios entre Montevideo e Interior.
Surge así la necesidad de realizar una estimación de la cantidad de población elegible en las zonas omisas del Censo, con el fin de estimar el impacto en los umbrales principalmente de los programas TUS y en la distribución por región de las partidas de beneficios.
La imputación de las zonas omisas del Censo debe realizarse bajo un enfoque que considere la distribución espacial de la omisión y de las variables a imputar. Los métodos clásicos para la imputación de datos faltantes (hot deck, cold deck, regression imputation, imputación múltiple, entre otros) no necesariamente consideran la estructura de correlación espacial de la variable a imputar. En particular el desarrollo teórico de lo que se denomina "Datos de Área" en estadística espacial, brinda un marco de análisis apropiado para el problema de investigación, permitiendo realizar la imputación como predicciones de modelos espaciales autorregresivos. A continuación se presenta una breve reseña del marco teórico utilizado, especificando las principales definiciones que hacen al cuerpo teórico de esta rama de la Estadística Espacial.
2. Estadística Espacial y Datos de Área
Dentro de la Estadística espacial según Gaetan y Guyon (2010), existen tres grandes áreas de estudio: Análisis de Patrones de Puntos (spatial point pattern), Geoestadística, y lo que se denomina Datos de Área. En Análisis de Patrones de Puntos el interés se centra en el lugar en donde ocurrirán los eventos. Se utiliza por ejemplo en epidemiología, y se concentra en la modelización de procesos estocásticos en tiempo y espacio. En el segundo caso, los datos pueden medirse en un principio en cualquier punto del espacio (datos continuos). El interés no es el patrón de puntos observados en sí mismo, sino en la predicción sobre un espacio continuo de una variable de interés medida en los sitios observados. Cuando los datos espaciales son observados en polígonos, se los definen como Datos de Área. En la mayoría de los casos los polígonos corresponden a unidades administrativas, como ser una zona censal, un departamento, país, etc. Los datos observados son frecuentemente agregados dentro de los límites del polígono, como por ejemplo totales o promedios dentro de las áreas administrativas. Los datos de área son datos discretos.
En el caso de Geoestadística, las distancias sobre una superficie continua son la base para determinar la estructura de la autocorrelación espacial. En el caso de Datos de Área no existe una noción de distancia euclidea, si no que se deben definir estructuras de vecindad-cercanía entre los polígonos. En una superficie con polígonos, se define una partición del conjunto (excluyendo la observación i) separando los polígonos que son vecinos de la observación i del resto de las observaciones. Así se conforma un grafo dirigido que describe la dependencia espacial entre los datos. A cada polígono en la vecindad a su vez se le pueden asignar diferentes pesos, que reflejen la intensidad de la dependencia espacial. Esta diferencia entre Geoestadística y Datos de Área es fundamental, ya que la estructura de vecinos es un hiperparámetro del modelo, teniendo el/la investigador/a varias alternativas para su definición. En el segundo caso es el/la investigador/a quien introduce la estructura de vecinos.
El presente trabajo corresponde a Datos de Área y las unidades de observación son las zonas censales (manzanas) del departamento de Montevideo. A continuación se presentan una serie de conceptos básicos dentro del análisis de Datos de Área, comenzando por la definición de vecindad-cercanía espacial.
2.1. Definiciones
El primer concepto fundamental es el de la matriz de pesos espaciales, en donde se refleja la estructura de vecinos seleccionada por el/la investigador/a. La matriz W se define en dos pasos, el primero en donde se define qué polígonos son vecinos, definiendo así una matriz binaria (matriz de conectividad), asignando el valor uno a aquellos polígonos que se definan como vecinos. En un segundo paso se establece un peso a los vínculos entre polígonos definidos en el paso anterior, utilizando en la gran mayoría de los casos métodos basados en distancia.
Existen varias formas de definir los vecinos. Uno de los criterios más utilizados es el de contigüidad, en donde se definen como vecinos aquellos polígonos que compartan bordes o vértices con la observación. Otros criterios pueden ser los k- vecinos más cercanos, o los determinados por radios de distancia.
La matriz W es la base del cálculo de la autocorrelación y de la estimación de modelos espaciales autorregresivos. Se dice que la matriz W está estandarizada cuando la suma de sus filas es uno. Cuando esto se cumple el valor propio principal de la matriz es uno (una de las propiedades necesarias para que un proceso espacial autorregresivo sea no divergente, LeSage y Pace, 2009) además de que la interpretación de los parámetros es más sencilla.
Uno de los estadísticos más utilizados para contrastar la existencia de autocorrelación espacial es el Índice de Moran, que se define de la siguiente manera:
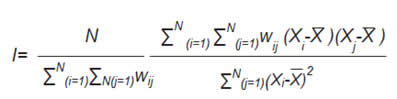
donde N es el número de observaciones, X es la variable de interés y w_ij son los pesos de la matriz W. Los valores de I se encuentran entre -1 y 1. Cuando se acerca a cero indica un patrón espacial aleatorio (no hay autocorrelación). Existen dos formas de interpretar la hipótesis nula de no existencia de autocorrelación espacial:
-
las observaciones son mutuamente independientes, o
-
cada permutación de las observaciones xi es igualmente probable
Se puede demostrar que la distribución asintótica del Índice de Moran escalado por una constante es N(0,1) (Gaetan y Guyon, 2010).
2. 2. Modelos Espaciales Simultáneos Autorregresivos (SAR)
Los modelos SAR son la extensión espacial de un modelo de regresión lineal, incluyendo un término correspondiente a la estructura espacial autorregresiva. Son una generalización de los procesos autorregresivos de series de tiempo.
El modelo espacial autorregresivo de primer orden se define como:
Y=ρWY+ε
donde Y es un vector columna de variables dependientes, W es la matriz de pesos espaciales y ε es un vector de errores aleatorios donde εi son i.i.d y N(0,σ2), con σ2 constante.
El término WY se denomina "rezago espacial". Bajo el supuesto de que (I-ρW) es no singular se tiene que:
Y=(I-ρW)(-1) ε
Al modelo presentado anterioremente se le denomina espacial autorregresivo puro, ya que sólo considera como variable explicativa a la dependiente rezagada. Los modelos de este tipo son estimados por Máxima Verosimilitud (LeSage y Pace, 2009).
3. Spatial Oblique Decision Tree (SpODT)
SpODT (Gaudart et al., 2015) es un método no paramétrico para encontrar clusters espaciales basado en los árboles de clasificación y regresión (CART).
En CART, para cada variable se busca un umbral que particione al espacio de la variable en dos clases, optimizando algún criterio definido a priori. Se realizan particiones binarias recursivas, hasta alcanzar una determinada regla de parada. Aplicado a datos espaciales, el CART busca entre las coordenadas planares {xi,yi } (de cada ubicación Mi) un umbral o límite entre clases espaciales tal que la media de la variable de interés sea lo más diferente posible entre las dos clases. El algoritmo CART lleva a obtener clases rectangulares, proporcionando particiones perpendiculares de las longitudes y latitudes proyectadas. El algoritmo SpODT es una variante de CART que proporciona una partición oblicua al área de estudio, que es más apropiada a la forma de los datos espaciales. La forma funcional puede ser escrita como:
zi=f(xi,yi )+εi
donde {xi,yi } son las coordenadas planares para cada punto Mi,i=1,…,N y εi R. La función f(xi,yi ) se define como:
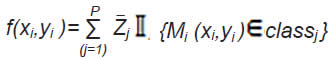
donde classj para j=1,…,P son las P clases finales después de particionar el área de estudio, y zj=1/Nj ∑(Mi ![]() classj)zi es el promedio de los valores observados de los Nj puntos Mi pertenecientes a la clase j (classj).
classj)zi es el promedio de los valores observados de los Nj puntos Mi pertenecientes a la clase j (classj).
El problema principal es entonces determinar el conjunto de clases classj para j=1,… ,P. Los límites entre las regiones estarán definidos por rectas sj(xi,yi )=axi+byi+c=0. Estos límites, o direcciones de partición, se determinan recursivamente por cada punto de la muestra, denotado como el nodo ξ, correspondiente al área de estudio al comienzo del algoritmo, o a una zona (clase geográfica) obtenida como resultado de una partición previa. El nodo ξ es particionado en dos clases, por la dirección sj (xii,yi). Si sj(xi,yi )≤0 entonces el punto Mi pertenecerá al nodo "hijo" (jl) de la izquierda del árbol. Si no, el punto Mi pertenecerá al nodo "hijo" de la derecha (jr). Para cada nodo ξ constituido por el conjunto de n(ξ) puntos, el algoritmo busca, entre el conjunto S de todas las funciones lineales de (xi,yi) la función si(xi,yi ) tal que:
![]()
Gaudart, Poudiougou, Dicko y Doumbo (2005) demuestran que el conjunto S de funciones que particionan el área de estudio es de cardinal finito. Existe un número infinito de líneas que particionan el conjunto de puntos en dos subclases, sin embargo, muchas de ellas llevan a la misma clasificación, particionando el conjunto de puntos en forma idéntica. El algoritmo debe identificar las posibles líneas a analizar como candidatas a particionar el conjunto de puntos. Para este propósito el algoritmo usa propiedades relacionadas al orden de las abcisas de los puntos a ser particionados, después de una rotación del eje de las x. Luego, el algoritmo realiza una partición vertical de las imágenes de las x para cada rotación. Al igual que en CART, las particiones se hacen recursivamente hasta alcanzar una determinada regla de parada. Para más detalle ver Gaudart et al. (2005).
4. Metodología
La metodología se desarrolla en las siguientes etapas:
-
Definición de las regiones de imputación.
Utilizando el algoritmo SPOdT se construye una regionalización de la superficie, de acuerdo a la variable proporción de hogares elegibles del programa TUS en las zonas censales.
-
Ajuste de modelos SAR con diferentes rezagos para las distintas regiones y selección del modelo con menor error de validación cruzada.
Para las regiones encontradas se obtienen los correlogramas por contigüidad y por clases de distancia (Bivand, Pebesma y Gómez Rubio, 2013; Oden, 1984) basados en el Índice de Moran. En el primer caso se considera como rezago espacial a los polígonos adyacentes, considerando distintas matrices de pesos espaciales W para cada rezago. En el segundo caso el rezago espacial se construye considerando los polígonos que se encuentran a una determinada distancia, construyendo así clases de distancia equidistantes entre sí, con una matriz W para cada una de las clases. Según la significación de los rezagos se elige un umbral de distancia para cada región y se ajustan modelos SAR cada 100 metros hasta alcanzar el umbral. Para cada modelo se estima el error de validación cruzada, y se selecciona el modelo correspondiente al rezago de menor error.
-
Ajuste del modelo SAR para el mapa global. Se selecciona el rezago de distancia de menor error de validación cruzada.
Se realiza el mismo procedimiento implementado en cada región para el mapa global, y se elige el rezago correspondiente al modelo de menor error de validación cruzada.
-
Comparación de resultados entre los modelos SAR locales y el global.
Se comparan los errores de validación cruzada de los modelos locales con el modelo global y se realizan pruebas de diagnóstico.
-
Imputación de la cantidad de hogares elegibles para el programa TUS. Con las predicciones del modelo seleccionado en el paso anterior se obtiene una estimación de la población elegible para el programa TUS en las zonas omisas en Montevideo.
5. Descripción de la base de datos
Las bases cartográficas con las que se trabajan corresponden a las actualizadas por el Censo 2011. Las zonas censales son unidades de muestreo en la selección de la muestra de la ECH.
Tabla 1. Clasificación de Zonas sin información. Montevideo. 2011

Notas:
* En el total de zonas no se tienen en cuenta las zonas definidas como "zonas verdes". Ejemplos de zonas verdes son los parques, canteros, reservas naturales, etc. Estas zonas no se censan y no se toman en cuenta para la imputación.
** Las zonas mixtas son aquellas en donde se encuentran casos de Moradores Ausentes y de Formato Papel.
Fuente: Elaboración propia en base a los datos del Censo de Población y Viviendas de Uruguay, 2011.
Existen varios tipos de omisión. El primero es en donde el/la empadronador/a2 releva el domicilio, pero el/la censista no. Se tiene un registro de la existencia de la vivienda, pero no se tiene información de quienes residen en ella. A este caso se lo denomina "Morador Ausente". Al estar registrada en el marco censal, la vivienda tiene posibilidades de ser seleccionada en la ECH. Si bien no se tienen datos al momento del censo sobre la cantidad de población elegible residente en la vivienda, al no quedar excluida del sorteo de la ECH, no genera un problema de marco.
El segundo es consecuencia de una operativa de emergencia al final del relevamiento del Censo. Se decidió relevar solamente los datos referentes a la composición del hogar, es decir, sexo, edad y relación de parentesco, en un cuestionario papel. Para estos hogares no es posible calcular el ICC, pero sí se tiene algún tipo de información que puede ser de importancia para determinar si el hogar es población elegible o no, como ser la cantidad de menores de 15 años. A estos casos se los denomina "Formato Papel". Como en el caso anterior, al no excluirse la vivienda del marco, no tiene consecuencias graves sobre la ECH, sí sobre la estimación de población elegible al momento del Censo.
El tercer caso es en el que en donde la vivienda no fue relevada ni por el/la empadronador/a, ni por el/la censista. Para poder corroborar esta situación es necesaria una fuente externa de información, ya que en el marco del INE no hay registros de estos domicilios. El MIDES realiza un relevamiento permanente en zonas socioeconómicamente vulnerables que permitió identificar algunos de estos casos en zonas censales que se encontraban vacías según el Censo. El trabajo que el MIDES realiza en campo es dirigido, y no es completo, es decir que no es posible identificar a todas las zonas que fueron omitidas completamente por el Censo. Sí se obtiene una cota inferior para esta cantidad, no siendo posible identificar el resto por no contar con fuentes externas oficiales que lo permitan.
El tercer caso sí tiene consecuencias importantes sobre las estimaciones de la ECH ya que estas zonas no son incluidas en el marco. El error que implique esta omisión se arrastra a todas las ECH futuras hasta una nueva actualización del marco.
La distribución geográfica de las zonas sin información y de la población elegible del programa TUS se presenta en el Gráfico 1. Si se compara la distribución de zonas omisas con la de las zonas sin información, se observa que tienen un patrón similar, confirmando que la omisión se concentró en zonas socioeconómicamente más vulnerables. El patrón no es homogéneo, habiendo mayor concentración en algunos sectores del mapa.
Gráfico 1. Distribución espacial de la población elegible del programa TUS y de las zonas omisas
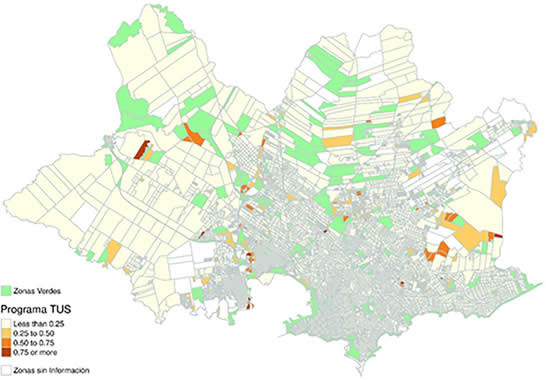
Fuente: Elaboración propia en base a la cartografía del Instituto Nacional de Estadística y a los datos del Censo de Población y Viviendas de Uruguay, 2011.
6.1. Definición de las regiones de imputación (SpODT)
La implementación se realiza con el paquete SpODT de R. Se imputarán aquellas zonas omisas de las regiones encontradas con un porcentaje de población elegible mayor a un 5 % (550 zonas).
Gráfico 2. Regiones de imputación definidas por el algoritmo SpODT
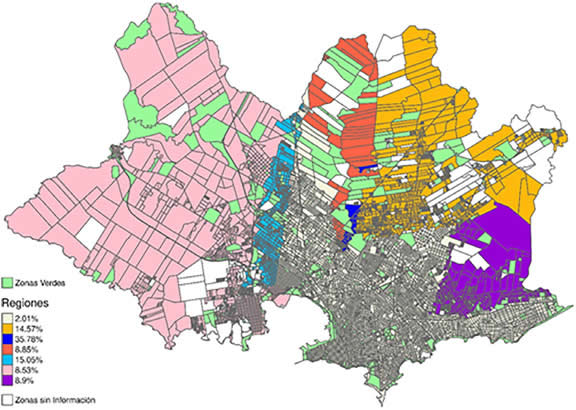
Fuente: Elaboración propia en base a la cartografía del Instituto Nacional de Estadística.
El mapa se divide en 7 regiones en total. Del total de regiones sólo una tiene un porcentaje de población elegible menor al 5% y corresponde a la zona del centro del mapa más la costa este del Departamento. La región con más alta concentración es la Región 2 del mapa. Es una región pequeña y presenta la particularidad de ser la única con una discontinuidad en el espacio. Se encuentra rodeada de zonas verdes y omisas.
La región del oeste de Montevideo (Región 5) es la más identificable en la partición obtenida, separada por una región "franja" (Región 4) con mayor porcentaje de población elegible. La zona noroeste del Departamento es la que presenta zonas omisas de gran superficie, y dentro de ella se encuentran dos regiones (Región 1 y 3). Por último, la región delimitada en la zona de Bañados de Carrasco incluye parte de Malvín Norte y de Carrasco Norte (Región 6).
6.2. Ajuste y elección de modelos SAR para las regiones seleccionadas
En cada región se realiza un correlograma por contigüidad y por clase de distancia basados en el I de Moran, los resultados se presentan en el Apéndice.
Basados en la significación de los Índices de Moran para los rezagos de los correlogramas se elige una distancia máxima para la prueba de los modelos. Luego se ajusta un modelo SAR para los rezagos múltiplos de 100 metros hasta el rezago máximo encontrado, y se realiza una validación cruzada basada en k- folds, con k=20 para cada modelo ajustado. Se selecciona el modelo con menor error de validación cruzada.
A continuación se presentan la estimación de los parámetros de los modelos con menor error de validación cruzada para las seis regiones encontradas, el rezago asociado, el p valor de la prueba de razón de verosimilitudes y el p valor asociado a la autocorrelación de los residuos realizada con el test de Moran (Bivand, Pebesma y Gómez Rubio, 2013).
Tabla 2. Resultados del ajuste de los modelos SAR locales con menor error de validación cruzada

Fuente: Elaboración propia.
A excepción de la región 6, en donde el modelo con menor error de validación cruzada corresponde a un rezago de 600 metros, los rezagos encontrados varían entre 200 y 300 metros. El parámentro ρ es significativo en todos los casos, y los residuos no presentan autocorrelación espacial según el test de Moran. En las regiones 3 y 5 la "intensidad" de la dependencia espacial es menor a la de las otras regiones. El error global de validación cruzada se calcula como:
![]()
6.3. Modelo Global
A continuación se presentan los correlogramas basados en contigüidad y en clases de distancias para el mapa de Montevideo.
Gráfico 3. Correlogramas basados en el I de Moran por contigüidad y por clases de distancia para el mapa de Montevideo
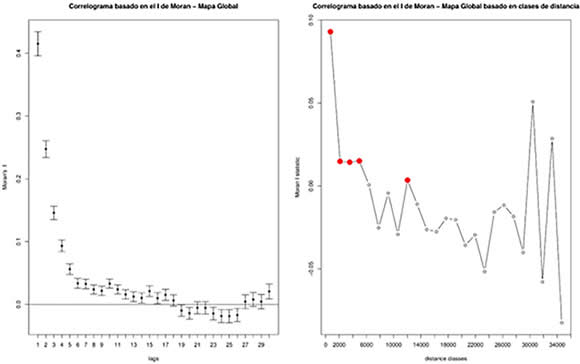
Fuente: Elaboración propia.
Como se puede observar en el correlograma basado en clases de distancias, aparece un rezago significativo hasta una distancia de aproximadamente 5.000 metros. Luego en el rezago de 12.000 metros vuelve a ser significativo. Según el basado en contigüidad, los rezagos son significativos hasta el número 17. Como son polígonos irregulares, no puede afirmarse que cada rezago basado en contigüidad tenga la misma distancia, por lo que se decide explorar los modelos hasta un rezago de 5.000 metros. No se consideran los rezagos que vuelven a ser significativos a distancias mayores en los correlogramas, ya que se presume que lo que capta es una discontinuidad en el mapa del fenómeno a estudiar.
Al igual que para los modelos locales, se prueban modelos SAR en rezagos múltiplos de 100, hasta el umbral de 5.000 metros. Los resultados del modelo con menor error de validación cruzada se presentan a continuación (Tabla 3).
Tabla 3: Resultados del ajuste del modelo global con menor error de validación cruzada.

Fuente: Elaboración propia.
El error de validación cruzada para el modelo SAR global es apenas mayor que para el obtenido con los modelos locales. Sin embargo los errores del modelo global muestran correlación espacial según el test de Moran. Esto puede deberse a las características de la región 6, en donde el rezago de menor error de validación cruzada es de 600 metros, disímil con el del resto de las regiones. Esto puede hacer que el modelo global, con un rezago de 200 metros para toda la superficie, presente correlación espacial en los residuos. Se decide entonces imputar la población elegible en las zonas omisas con los modelos SAR locales obtenidos a partir de la regionalización.
6.4. Imputación
El total de hogares población elegible estimado en las zonas omisas es de 1.058 hogares (5% aproximado del total en zonas no omisas).
Tabla 4. Quintiles de la proporción de hogares imputada.

Fuente: Elaboración propia.
De los valores de los quintiles para las proporciones imputadas se puede decir que hasta un 80% son proporciones bajas, de menos de un 16% aproximadamente. Sólo un 20% supera estos valores y con una proporción máxima de 62%.
7. Conclusiones y líneas futuras de investigación
Luego de aplicar el algoritmo SpODT tomando como variable de respuesta a la proporción de hogares población elegible del Programa TUS, se obtiene una partición con siete regiones, de las cuales se excluye una del análisis por la baja proporción de hogares población elegible. Para el resto de las zonas, se ajustan modelos SAR variando el rezago de a 100 metros, hasta un rezago límite que se define a partir de la observación de los correlogramas basados en el Índice de Moran (por clases de distancia y por contigüidad). Salvo en una región, los rezagos que presentan menor error de validación cruzada corresponden a los 200 o 300 metros.
Por otro lado, se estima un modelo global, considerando la totalidad del mapa. Con el mismo procedimiento utilizado en las regiones, se encuentra que el mejor modelo según el criterio de validación cruzada es el correspondiente a un rezago de 200 metros, presentando un error apenas mayor que en los obtenidos con los modelos locales. Sin embargo, el modelo global presenta autocorrelación espacial en los residuos, según el test de Moran, probablemente debido a la región 6 que se muestra heterogénea respecto a las demás, con un rezago de 600 metros.
Por último, se obtiene una estimación del total de hogares población elegible en las zonas omisas, representando un 5% de la población elegible estimada actual.
Como líneas futuras de investigación se detallan los siguientes problemas a analizar: Estimar la varianza de la predicción obtenida con los modelos locales: para este trabajo se obtuvo una estimación puntual, y en el caso de que el modelo global hubiese resultado más adecuado que los locales sería más sencillo. Se presenta el problema de realizar una estimación de varianza con los modelos locales agregados, que debería enfocarse en un principio con métodos de remuestreo.
Probar el método con una diferencia más acentuada de los rezagos entre las regiones. El mapa de Montevideo en las seis regiones encontradas es homogéneo en cuanto a los rezagos que minimizan el error de validación cruzada, a excepción de un caso. Surge entonces la pregunta de cuáles serían los resultados si la variable de interés fuera totalmente heterogénea entre regiones. Mediante simulación podrían evaluarse distintos escenarios con diferentes grados de heterogeneidad entre regiones, de forma que permita arribar a una conclusión más general en cuanto a la metodología utilizada para la selección de los modelos locales y el global.
Incorporar variables explicativas al modelo. En este trabajo no se incorporaron variables como la cantidad de menores por hogar, que pueden tener un poder explicativo fuerte cuando se quiere determinar si un hogar es población elegible. Tampoco se consideraron los datos faltantes dentro de zonas con datos completos, es decir, las zonas que se imputaron se encuentran completamente sin información y puede haber zonas mixtas en donde hayan datos completos y faltantes. Se podría adaptar la metodología de forma que incorpore estos dos niveles de información.
1. Una versión anterior fue presentada en el Congreso Interamericano de Estadística (CIE) 2017, Rosario, Argentina.
2. Previo al relevamiento del Censo se realiza una enumeración denominada precenso en donde un/a empadronador/a releva los domicilios por observación. Este relevamiento constituye la lista de partida para el/la censista.
Anexos
Gráfico 4. Correlogramas basados en el I de Moran por clases de distancia para las regiones definidas por el algoritmo SpODT
Fuente: Elaboración propia.
Gráfico 5. Correlogramas basados en el I de Moran por contigüidad para las regiones definidas por el algoritmo SpODT
Fuente: Elaboración propia.
Referencias bibliográficas
1. Bivand, R., Pebesma, E. y Gómez Rubio, V. (2013). Applied Spatial Data Analysis with R. New York, EEUU: Springer. [ Links ]
2. Gaetan, C. y Guyon, X. (2010). Spatial Statistics and Modeling. New York, EEUU: Springer-Verlag. [ Links ]
3. Gaudart, J., Poudiougou, B., Dicko, A., y Doumbo, O. (2005). Oblique decision trees for spatial pattern detection: optimal algorithm and application to malaria risk. BMC Medical Research Methodology, 5(1). [ Links ]
4. Gaudart, J., Graffeo, N., Coulibaly, D., Barbet, G., Rebaudet, S., Dessay, N., ... y Giorgi, R. (2015). Spodt: An r package to perform spatial partitioning. Journal of Statistical Software, 63(16), 1-23. [ Links ]
5. LeSage, J. y Pace, R. K. (2009). Introduction to Spatial Econometrics. Florida, EEUU: Chapman and Hall, CRC Press. [ Links ]
6. Ministerio de Desarrollo Social (2013). ¿Qué es el Índice de carencias críticas? Serie de documentos "Aportes a la conceptualización de la pobreza y la focalización de las políticas sociales en Uruguay" [ Links ].
7. Oden, N. L. (1984). Assesing the significance of a Spatial Correlogram. Geographical Analysis. Vol. 16, Issue 1, pp. 1 - 16. [ Links ]