










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkGeoacta
versión On-line ISSN 1852-7744
Geoacta vol.37 no.1 Ciudad Autónoma de Buenos Aires ene./jun. 2012
TRABAJOS DE INVESTIGACIÓN
Atributos AVO/AVA de alta resolución utilizando very fast simulated anneling
Daniel O. Pérez y Danilo R. Velis
Facultad de Ciencias Astronómicas y Geofísicas, UNLP; y CONICET, Argentina.
dperez@fcaglp.unlp.edu.ar; velis@fcaglp.unlp.edu.ar
RESUMEN
En este trabajo presentamos un nuevo método de inversión para obtener atributos AVO/AVA de tipo sparse-spike a partir de datos sísmicos prestack. El método propuesto apunta a obtener el menor número de reflectores que, convolucionados con la ondícula, ajustan al dato. Este método es una extensión, aplicada a datos prestack, de un trabajo anterior sobre deconvolución sparse-spike aplicado a datos poststack. Debido a la alta no linealidad del problema inverso, que incluye la determinación en tiempo de un número dado de reflectores, se busca la solución usando el algoritmo de optimización global conocido como Very Fast Simulated Annealing (VFSA). Contrariamente a otros métodos que también buscan soluciones de tipo sparse, y donde el número de incógnitas coincide con el número de muestras del dato sísmico, en la estrategia propuesta el número de incógnitas es mucho menor. Como consecuencia, las matrices a invertir son pequeñas y el proceso de inversión resulta relativamente económico en términos de costo computacional, aún cuando la inversión se realiza utilizando simulated annealing. La técnica permite, además, determinar incógnitas adicionales como por ejemplo una rotación de fase de la ondícula (para su calibración a partir de la estimación inicial) o su frecuencia central (para compensar efectos de atenuación). Una ventaja de utilizar VFSA es que la incertidumbre de las soluciones puede ser estimada estocásticamente, aprovechando el gran número de soluciones que se ponen a prueba durante el proceso de inversión. Los atributos AVO/AVA de alta resolución que se obtienen luego de la inversión incluyen el Intercept y el Gradient, o sea los coeficientes de la aproximación de Shuey de dos términos de las ecuaciones de Zoeppritz, las que son utilizadas para modelar la variación con el ángulo de incidencia del coeficiente de reflexión. No obstante, la incorporación de otras aproximaciones es inmediata. Los resultados obtenidos utilizando datos sintéticos 1D y 2D muestran que la metodología propuesta es robusta en presencia de ruido aleatorio, incluso cuando el número de reflectores es desconocido a priori y la ondícula utilizada no es exacta. También se observa la capacidad del método para resolver reflectores cercanos y conservar la continuidad lateral de los mismos. Sobre datos de campo el método propuesto mostró buen comportamiento, permitiendo hallar soluciones de alta resolución que honran al dato observado.
Palabras clave: Atributos AVO; Sparse-spike; Simulated annealing; Alta resolución; Shuey.
ABSTRACT
We present a new inversion method to obtain sparse-spike AVO/AVA attributes from prestack seismic data. The proposed method aims to find the smallest number of reflectors that, when convolved with the source wavelet, fit the data. This method is an extension to prestack data of an earlier work on sparse-spike deconvolution that was applied to poststack data. Due to the high nonlinearity of the inverse problem, which includes the determination of the time location of a given number of reflectors, we use the global optimization algorithm known as Very Fast Simulated Annealing (VFSA). Unlike other inversion methods that look for sparse solutions in which the number of unknowns is equal to the number of samples of the seismic data, in the proposed strategy the number of unknowns is much smaller. As a result, the matrices used during the inversion are small and the process is relatively cheap in terms of computational cost, despite the fact that the inversion is carried out using simulated annealing. The technique can also be used to determine additional unknowns such as a constant phase rotation of the wavelet (to calibrate an initial estimate) or its central frequency (to compensate for attenuation effects). One advantage of the method is that the uncertainty of the solutions can be estimated stochastically, taking advantage of the large number of solutions that are tested during the inversion process. The high resolution AVO/AVA attributes obtained after the inversion include both the Intercept and the Gradient, i.e. the coefficients of the two-terms Shuey's approximation of the Zoeppritz equations, which are used to model the variation of the reflection coefficient with the incidence angle. However, the incorporation of other approximations is immediate. Results using 1D and 2D synthetic data show that the proposed method is robust under noisy conditions, even in the case where the number of reflectors is not known a priori and the utilized wavelet is inaccurate. It is also noted that the method is not only capable of resolving close reflectors, but also it preserves the lateral continuity of the events. On field data the method shows a good behavior, providing high-resolution images that honor the observed data.
Keywords: AVO attributes; Sparse-spike; Simulated annealing; High resolution; Shuey.
INTRODUCCIÓN
Uno de los objetivos centrales de la inversión de datos sísmicos prestack consiste en determinar contrastes entre las propiedades físicas de las rocas del subsuelo, tales como las velocidades de las ondas P, de las ondas S y densidades, a partir de la información contenida en la variación de las amplitudes de las ondas sísmicas reflejadas en las interfases geológicas en función del ángulo de incidencia. Dicha variación, llamada AVA (amplitud vs. ángulo) o AVO (amplitud vs. offset), puede modelarse mediante las ecuaciones de Zoeppritz (Zoeppritz, 1919; Yilmaz, 2001). Estas ecuaciones expresan los coeficientes de transmisión y reflexión en función del ángulo de incidencia de una onda plana (compresional o de corte) que incide en una interfase que separa dos medios elásticos homogéneos. Debido a que estas ecuaciones no son lineales su utilización en los problemas de inversión es poco práctica. Asumiendo que los contrastes entre las propiedades de los medios son pequeños se desarrollaron aproximaciones lineales con el fin de facilitar la interpretación de estas ecuaciones (Bortfeld, 1961; Aki y Richards, 1980; Shuey, 1985; Smith y Gidlow, 1987; Fatti y otros, 1994; Verm y Hilterman, 1995). En forma general estas aproximaciones se pueden expresar mediante
![]()
donde a(?) es la amplitud del coeficiente de reflexión o transmisión en función del ángulo de incidencia ? , k x son parámetros que dependen de las propiedades físicas de las rocas (velocidades y densidades a cada lado de la interfaz), g (?) k son funciones que dependen exclusivamente del ángulo de incidencia, y n (n=2,3) es el orden de la aproximación (Pérez y Velis, 2011a, 2011b). Estas aproximaciones son válidas para ángulos menores al ángulo crítico.
Por lo general un registro sísmico contiene varios reflectores y la variación de la amplitud del coeficiente de reflexión (o transmisión) con el ángulo de incidencia en cada uno de ellos se puede expresar según la ecuación anterior. Es importante destacar que debido a que el dato sísmico posee ruido, es incompleto, de banda limitada y que el ángulo de incidencia generalmente tiene un valor máximo menor a 40 �� , existe gran ambigÜedad en el modelo de reflectividad que ajusta al dato. En otras palabras, dado un conjunto de trazas sísmicas para varios ángulos de incidencia, existen diferentes conjuntos de reflectores representados por la ecuación (1) que, convolucionados con la ondícula, reproducen el dato con el mismo grado de precisión. Este grado de ambigÜedad se puede reducir incorporando restricciones e información adicional al problema inverso con el fin de limitar el espacio de posibles soluciones. A diferencia de las soluciones provistas por un análisis de AVA convencional este trabajo se centra en la búsqueda de soluciones de tipo sparse-spike. Esta restricción permite obtener soluciones de alta resolución útiles para caracterizar reflectores muy próximos entre sí o simplemente para caracterizar los reflectores más significativos (Pérez y Velis, 2011a, 2011b).
Una solución de tipo sparse-spike es aquella que nos permite representar la traza sísmica como la convolución de una serie poco densa de reflectores con una ondícula. Dicha serie puede representarse a través de la siguiente ecuación (Velis, 2008):
![]()
donde M << L es el número de spikes (reflectores) de amplitud j a y tiempo j τ , L el número de muestras en la ventana de tiempo donde se realizará la inversión, y t d es la función impulso unidad, cuyo valor es la unidad si t = 0 y cero para cualquier otro valor de t .
Varios autores han realizado trabajos sobre inversión AVA de tipo sparse con excelentes resultados (Downton y Lines, 2003; Misra y Sacchi, 2008; Alemie, 2010, Alemie y Sacchi, 2011). Una de las principales diferencias entre el método propuesto en este trabajo y los métodos propuestos con anterioridad es que estos últimos estiman una solución de tipo sparse-spike considerando que el número de reflectores es igual al número de muestras en la ventana de tiempo utilizada para la inversión. La solución se obtiene maximizando una norma que mide cuán sparse es la solución. Como alternativa, en nuestro enfoque las soluciones sparse se obtienen fijando a priori el número M de reflectores. Con este criterio, intentamos obtener un conjunto de soluciones compuestas por el menor número posible de reflectores, lo que equivale a minimizar la norma 0 L. Este mismo enfoque fue utilizado por Velis (2008) en la deconvolución de tipo sparse-spike de datos poststack. La técnica propuesta en este trabajo es una extensión para datos prestack del método de deconvolución mencionado.
El método propuesto fue probado utilizando datos sintéticos prestack 1D y 2D corregidos por Normal Move Out (NMO), y considerando la aproximación de Shuey de dos términos. Mostramos cómo los atributos AVA de tipo sparse-spike pueden obtenerse con gran precisión a partir de datos con altos niveles de ruido, incluso cuando el número de reflectores es desconocido y la ondícula no es exacta. Con respecto a esta última, se incluyen una rotación constante de su fase y un ajuste en su frecuencia central como incógnitas adicionales durante el proceso de inversión. Asimismo, se aplicó el método a datos reales, obteniéndose soluciones de alta resolución que ajustan al dato de manera precisa y que exhiben una buena continuidad lateral. El análisis sugiere que el método es robusto ante la presencia de ruido e incertidumbre en la ondícula y número de reflectores. También se observa la capacidad del mismo para resolver reflectores cercanos. Asimismo, los resultados son consistentes cuando se invierte un conjunto grande de registros sísmicos.
METODO PROPUESTO
El modelo convolucional es utilizado como base del método de inversión. Este modelo asume que el medio está compuesto por una serie de capas planas, paralelas, homogéneas e isótropas. Las ondas convertidas y múltiples no son contempladas. Utilizando el modelo convolucional, la traza correspondiente al i-ésimo ángulo de incidencia i ? , con i=1,...,N, de un angle-gather corregido por NMO puede expresarse como
![]()
Donde ( ) 0 0 ω f ,j t es la ondícula sísmica, 0 fy 0 j incógnitas que representan la frecuencia central y la rotación de fase de la misma, ( ) t i r ? la serie de coeficientes de reflexión y ( ) t i n ? ruido aleatorio. La incorporación de las constantes 0 fy 0 j como parte de la inversión tiene como objetivo poder ajustar una ondícula al dato observado o realizar una calibración de la misma en caso de contar con una estimación deficiente.
Una secuencia de reflectores de tipo sparse-spike para el ángulo de incidencia i ? puede representarse según la ecuación (2) como:
![]()
Combinando las ecuaciones (1) y (4), la ecuación (3) puede reescribirse como
![]()
donde por simplicidad se omitió el término correspondiente al ruido. En forma matricial, para cada ángulo de incidencia se tiene
![]()
donde ( )T M1 Mn = x ,...,x ,...,x ,...,x 11 1n x , ( ) ( )T i L ? = s ,...,s 1 s y la matriz ( ) i A ? , de dimensión L´Mn , se puede expresar como
![]()
Donde Ak (?i ) con k =1,... ,n son submatrices de dimensión L´M que depende de la ondícula sísmica ( ) 0 0 ω f ,j t , los tiempos j τ y las funciones ( ) k i g ? de la forma

La ecuación (6) representa un sistema de ecuaciones lineales en términos de las incógnitas x , pero no lineal en términos de los tiempos j τ y las constantes 0 fy 0 j .
El vector xˆ óptimo puede estimarse minimizando la discrepancia entre el dato observado ( ) i s ? y el dato modelado sˆ( ) A( )xˆ i i ? = ? , por lo que definimos la función de costo
![]()
En la práctica minimizamos J respecto a ( ) M = τ ...τ 1 τ , 0 fy 0 j usando Very Fast Simulated Annealing (VFSA) (Ingber, 1989). En cada iteración del annealing, dados los valores estimados τˆ , 0 ˆf y 0 jˆ , el vector óptimo xˆ es estimado resolviendo el problema de mínimos cuadrados dado por la ecuación (9), lo que lleva a
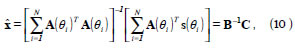
donde B es una matriz simétrica de dimensión Mn × Mn y C es un vector de dimensión Mn.
El proceso es iterativo. A partir de valores τˆ , 0 ˆf y 0 jˆ dados por el VFSA se construye la matriz ( ) i A ? y se calcula el vector óptimo xˆ utilizando la ecuación (10). Por medio de la ecuación (9) se calcula el valor de la función de costo J . Dependiendo del valor que toma la función de costo el VFSA decide si aceptar o rechazar la solución y propone nuevos valores de τˆ , 0 ˆf y 0 jˆ . Con estos nuevos valores se vuelve a estimar un nuevo vector óptimo xˆ y se vuelva a calcular J . El proceso iterativo termina cuando se alcanza un valor predeterminado de la función de costo, un número máximo de iteraciones o algún otro criterio de corte.
Sobre el Very Fast Simulated Annealing
Simulated annealing (SA) es un poderoso algoritmo de optimización no lineal cuyo objetivo es encontrar el mínimo global de una función independientemente del modelo inicial y que no requiere el cálculo de derivadas ni gradientes. El nombre proviene del proceso de recocido de metales, una técnica metalúrgica que consiste en calentar y luego enfriar el material de manera controlada para variar sus propiedades físicas. La evolución de las propiedades de un metal sometido al proceso de recocido fue estudiada por Metropolis y otros (1953) a través de métodos Monte Carlo. Kirkpatrick y otros (1983) generalizaron el concepto y lo aplicaron a problemas de optimización no lineal. Los parámetros desconocidos (el modelo) juegan el papel de las partículas en el metal y el estado de energía del sistema está representado a través de una función de costo. El proceso de simulación es iterativo. En cada paso la configuración del modelo (posición de las partículas) se selecciona a través de una distribución de probabilidad que depende de un parámetro de control llamado temperatura. Esta temperatura decrece gradualmente durante el proceso de optimización siguiendo un esquema de enfriado preestablecido. Cuando la temperatura es alta, el espacio de donde se escogen los parámetros del modelo es explorado de forma aproximadamente uniforme. A bajas temperaturas, se escoge preferentemente un modelo cuyo valor de energía (función de costo) es más bajo. Sin embargo, si el sistema es enfriado muy bruscamente, las partículas del material (incógnitas del modelo) no alcanzarán la configuración de mínima energía (mínimo global de la función), por lo que el esquema de enfriamiento es clave para un correcto funcionamiento del proceso. El modelo es aceptado o rechazado en cada iteración según el criterio de Metropolis. Este criterio establece que si el valor de la función de costo disminuye, el nuevo modelo es aceptado sin condiciones. En cambio, si el valor de la función de costo aumenta, el nuevo modelo es aceptado con una probabilidad no nula que depende de la energía y de la temperatura. A mayor temperatura esta probabilidad de aceptación es mayor. A menor temperatura, por otro lado, la probabilidad de aceptación es menor, pero no nula. Esta estrategia permite aceptar soluciones que producen un incremento en la función costo evitando así quedar atrapado en mínimos locales. Se consigue la convergencia cuando, a bajas temperaturas, no se observa un decrecimiento significativo en el valor de la función de costo. VFSA es una modificación del SA clásico propuesta por Ingber (1989). Las principales diferencias residen en el esquema de enfriado y en la distribución de probabilidad utilizada para la elección de los modelos. VFSA utiliza una distribución del tipo Cauchy de cola larga que permite que el espacio de los modelos sea explorado más eficientemente que utilizando una distribución gaussiana o uniforme como hacen otros algoritmos de SA convencionales. Un esquema de enfriado más veloz permite acelerar la convergencia sin limitar la habilidad del método para escapar a los mínimos locales.
Sobre la aproximación de Shuey
La ecuación (1) es la forma general de la aproximación lineal a las ecuaciones de Zoeppritz. En este trabajo se utilizó la aproximación de Shuey (1985), cuya expresión para el caso del coeficiente de reflexión de la onda P es:
![]()
donde el parámetro P R , llamado Intercept, y el parámetro G , llamado Gradient, dependen de las propiedades elásticas de los medios según las siguientes ecuaciones:
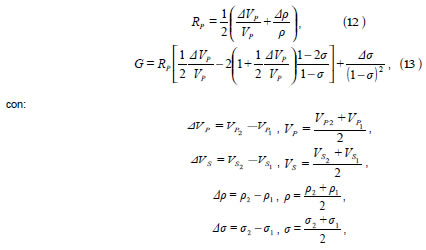
Siendo P1 V , S1 V , P2 V , S2 V , 1 ? , 2 ? , 1 s y 2 s las velocidades, densidades y los coeficientes de Poisson a cada lado de la discontinuidad sobre la que incide la onda y ? el ángulo promedio entre el ángulo de incidencia ? y el ángulo de transmisión ?T :
![]()
Los ángulos ? y ?T deben ser reales y menores a 90° . Para ángulos de incidencia ? < 30 el ángulo ? se puede aproximar por ? y el tercer término de la ecuación (11) se puede omitir sin que se produzcan, en general, errores significativos respecto a las ecuaciones de Zoeppritz (Shuey, 1985), por lo que la ecuación (11) se convierte en la clásica aproximación de dos términos (n=2):
![]()
La importancia de la aproximación de dos términos reside en las posibilidades de análisis que ofrece. Un gráfico de correlación (crossplot) entre los parámetros Intercept y Gradient obtenidos del dato sísmico usualmente muestra, en ausencia de hidrocarburos, un comportamiento característico según el tipo de rocas involucradas. En caso contrario, o sea ante la presencia de hidrocarburos, se observan desviaciones respecto a este comportamiento característico, por lo que dichos parámetros pueden ser utilizados como indicadores de la presencia de petróleo y/o gas (ver por ejemplo, Smith y Gidlow, 1987). Sin embargo, la interpretación de dichos gráficos no es sencilla debido a la complejidad del significado físico del Gradient (ecuación (13)), la compleja dependencia del Intercept y del Gradient con las propiedades no petrofísicas de las rocas, y los posibles efectos negativos causados por datos de pobre calidad y posíbles imprecisiones en la ondícula (Castagna y otros, 1998).
EJEMPLOS
Datos sintéticos 1D
Para analizar el comportamiento del método se generó un angle-gather corregido por NMO a partir de los modelos de velocidades y densidad representados en la Figura 1. El gather contiene 13 reflectores y consta de 31 trazas con ángulos de incidencia ( ° ° ) i ? Î 0 ,30 . La respuesta AVA se calculó utilizando las ecuaciones de Zoeppritz. Cada traza se obtuvo luego de convolucionar la serie de coeficientes de reflexión con una ondícula de Ricker de frecuencia central 30 0 f = Hz (Figura 2a). Al dato se le agregó ruido gaussiano con s = max | s (? ) | / 5 i,t t i (Figura 2b). Es decir, se trabajó con una relación señal-ruido (S/N) de 5. No obstante, la relación S/R para algunas trazas individuales es mucho menor. El intervalo de muestreo utilizado fue de 4 ms.
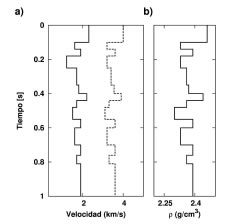
Figura 1. Modelo de velocidades 1D. a) Línea punteada, velocidad de la onda P. Línea contínua, velocidad de la onda S, b) densidad.
Figure 1. 1D velocity model. a) dashed line, P-wave velocity. Continuous line, S-wave velocity, b) density.
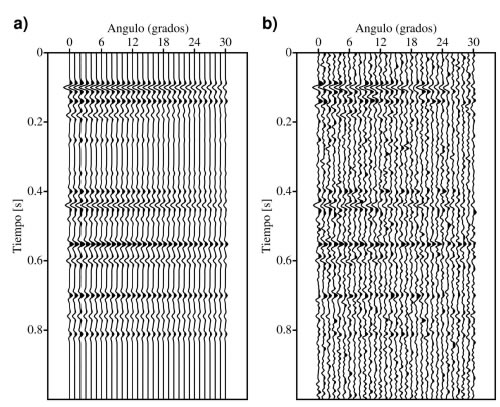
Figura 2. a) Gather sintético 1D sin ruido, b) gather sintético 1D con ruido.
Figure 2. a) Noise free synthetic gather, b) noisy synthetic gather.
Para estudiar el comportamiento del método de inversión ante la incertidumbre en el número de reflectores a buscar, se realizaron pruebas con M=13 (el número correcto) y M=18, ambas realizadas sobre el dato con ruido. En cada prueba, por propósitos estadísticos, se procedió a realizar 50 inversiones donde en cada inversión se utilizó una semilla diferente para el generador de números pseudoaleatorios utilizados por el VFSA . La frecuencia central 0 fy la rotación de fase 0 j para el ajuste de la ondícula de Ricker fueron incorporadas como incógnitas adicionales. El rango de búsqueda para 0 ffue de 22 a 55 Hz y para 0 j fue de -30 a 30 grados. Como criterio de corte se estableció que la inversión termine cuando el valor de la función de costo dado por la ecuación (9) fuera menor al nivel del ruido. Como solución final se tomó el promedio de las 50 soluciones. Nótese que si bien el dato se creó utilizando las ecuaciones de Zoeppritz, la inversión se realizó utilizando la aproximación lineal de Shuey de orden n=2 (ecuación (15)).
Las Figuras 3a y 3b muestran, respectivamente, el dato estimado mediante el promedio de los coeficientes de reflexión reconstruidos a partir del Intercept y Gradient invertidos y el residuo correspondiente (diferencia entre el dato observado y el estimado) para el caso con M=13. Asimismo las Figuras 3c y 3d muestran el dato estimado y el residuo para el caso con M=18. Se observa que el método ofrece buenos resultados. Todos los reflectores han sido encontrados y se consiguió un buen ajuste al dato libre de ruido (Figura 2a). Nótese que la relación señalruido es muy baja para algunos reflectores débiles, como aquellos ubicados entre 0.2 y 0.4 s. A pesar de ello, los mismos fueron recuperados correctamente.
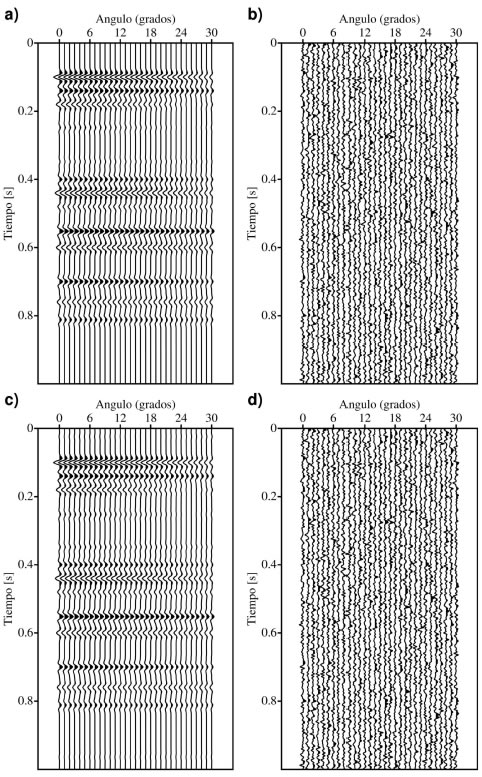
Figura 3. a) Resultado medio para M=13, b) residuo para M=13, c) resultado medio para M=18, d) residuo para M=18.
Figure 3. a) Average gather with M=13, b) residual with M=13, c) average gather with M=18, d) residual with M=18.
Las Figuras 4 y 5 muestran los valores del Intercept y del Gradient obtenidos a partir del modelo de velocidad (paneles a), los invertidos con M=13 y M=18 con sus respectivas desviaciones estándar (paneles b y c), y los obtenidos utilizando métodos de tipo convencional tales como un análisis muestra a muestra de Intercept/Gradient (paneles d) o una inversión por mínimos cuadrados (paneles e). El análisis muestra a muestra de Intercept/Gradient consiste en una inversión de amplitudes como describe Yilmaz (2001, sección 11.2). Por otro lado, la inversión por mínimos cuadrados corresponde a la solución dada por la ecuación (10) con M=n (ondícula conocida) y utilizando un preblanqueo adecuado para estabilizar la inversión de la matriz B. Naturalmente, estas dos soluciones "convencionales" presentan una muy baja resolución que dificulta la interpretación correcta de los atributos. En el segundo caso, debido al preblanqueo necesario para evitar inestabilidades, las amplitudes de los atributos estimados resultan además subestimadas. Contrariamente, las soluciones de tipo sparse-spike del método propuesto son de muy alta resolución y muestran un buen comportamiento en cuanto a las amplitudes estimadas, incluso en presencia de un nivel de ruido significativo y una gran incertidumbre en la ondícula. En este caso, los parámetros de la aproximación resultan estimados con precisión, en tanto que los valores relativamente bajos de las desviaciones estándar resaltan la consistencia de las soluciones. Es importante destacar que son esperables pequeñas diferencias entre los parámetros observados y estimados, no sólo debido a la presencia de ruido, sino también porque los datos fueron creados modelando la respuesta AVA por medio de las ecuaciones de Zoeppritz y la inversión fue realizada utilizando la aproximación de Shuey de dos términos. Nótense los impulsos espurios de pequeña amplitud en el caso con M=18 (Figuras 4c y 5c). Estos reflectores espurios surgen como consecuencia de realizar la inversión buscando un número de reflectores mayor al que realmente posee el dato. En estos casos el algoritmo procede a ubicar estos reflectores adicionales en aquellos tiempos donde produzcan una disminución del valor de la función de costo. En el caso de trabajar sobre datos sin ruido, dichos reflectores espurios tendrían amplitud prácticamente nula y su ubicación en tiempo sería consecuencia del comportamiento aleatorio del SA. En el caso de trabajar sobre datos que poseen ruido aleatorio, estos reflectores poseen una amplitud pequeña, y su ubicación en tiempo depende en parte de las características del ruido agregado, siendo más probable que sean ubicados en aquellos lugares donde la amplitud del ruido sea mayor

Figura 4. a) Intercept verdadero; b) Intercept medio estimado (M=13); c) Intercept medio estimado (M=18), y sus correspondientes desvíos estándar; d) Intercept estimado por medio de un análisis muestra a muestra de Intercept/Gradient; y e) Intercept estimado a través de una inversión por mínimos cuadrados.
Figure 4. a) Actual Intercept; b) mean estimated Intercept (M=13) ; c) mean estimated Intercept (M=18), and their corresponding standard deviations; d) estimated Intercept by means of a sample-by-sample Intercept/Gradient analysis; and e) least-squares estimated Intercept.
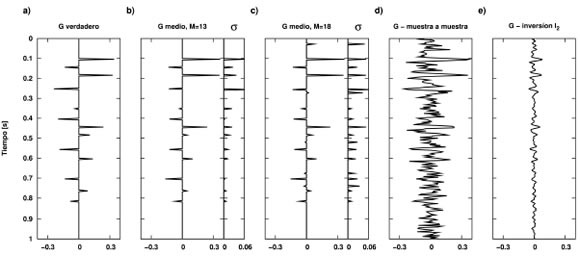
Figura 5. a) Gradient verdadero; b) Gradient medio estimado (M=13); c) Gradient medio estimado (M=18), y sus correspondientes desvíos estándar; d) Gradient estimado por medio de un análisis muestra a muestra de Intercept/Gradient; y e) Gradient estimado a través de una inversión por mínimos cuadrados.
Figure 5. a) Actual Gradient; b) mean estimated Gradient (M=13); c) mean estimated Gradient (M=18), and their corresponding standard deviations; d) estimated Gradient by means of a sample-by-sample Intercept/Gradient analysis; and e) leastsquares estimated Gradient.
Los valores medios invertidos para la frecuencia central 0 fy la rotación de fase 0 j para el ajuste de la ondícula fueron f 0 = 29,4 Hz y = 3.35 ° 0 j , respectivamente, con desviaciones estándar prácticamente despreciables. Estos resultados resaltan la capacidad del método para invertir con precisión la ondícula de Ricker. Al trabajar con datos de campo, sin embargo, es habitual desconocer la ondícula, o sólo contar con una estimación de ésta a partir del dato. En este caso el método propuesto puede ser utilizado para realizar una calibración de la misma , considerando como parte de los objetivos de la inversión la búsqueda de un valor de rotación de fase 0 j y un valor de corrección en la frecuencia central 0 df que mejoren el ajuste del dato sintético al dato observado.
La Figura 6 muestra el comportamiento de la función de costo J con respecto al número de reflectores buscados durante la inversión. Como es esperable, el valor de la función decrece a medida que el número de reflectores aumenta. Sin embargo, la curva muestra una tendencia asintótica al nivel del ruido cuando el número de reflectores buscados es más grande que el número verdadero, que en este caso es igual a 13. Esto sucede debido a que para valores grandes todos los reflectores ya han sido encontrados e incrementar dicha cantidad sólo contribuye a ajustar ruido no correlacionado, lo que no produce una disminución significativa del valor de la función de costo. Esta curva puede ser utilizada como guía para seleccionar el número apropiado de reflectores a buscar por ejemplo seleccionando M a partir de observar la zona en la cual la curva tiene máxima curvatura o comienza a aplanarse. En este sentido, cuando se utiliza un número mayor al correcto los resultados muestran que los reflectores "extra" son ubicados a diferentes tiempos según la inversión, pero en todos los casos sus amplitudes son cercanas a cero y no son visibles en el dato reconstruido. Por ello la selección de este parámetro no es crítica.
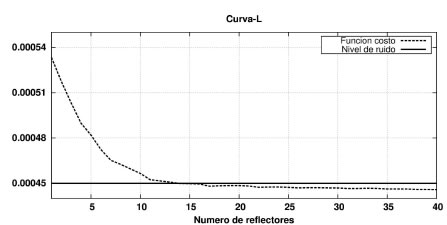
Figura 6. Variación de la función de costo según el número de reflectores buscados en la inversión.
Figure 6. Variation of the cost function when searching for different number of reflectors.
Datos sintéticos 2D
En este ejemplo se analiza la capacidad del método para preservar la continuidad lateral de los eventos horizontales en un modelo bidimensional y el comportamiento del mismo frente a datos que, a priori, no muestran un carácter sparse muy claro. A partir de datos de velocidad y densidad obtenidos a través de perfilajes de pozo (Figura 7) fue construido un modelo 2D de velocidad y densidad (Figura 8). A partir de este modelo se crearon 100 angle-gathers corregidos por NMO, con un intervalo de muestreo de 4 ms. Al dato se le agregó ruido gaussiano con s = max | s (? ) | /10 i,t t i , es decir S/N =10. Para generar el dato se utilizó el modelo convolucional y una ondícula de Ricker con 35 0 f = Hz. Como en el ejemplo 1D, la respuesta AVA se modeló utilizando las ecuaciones de Zoeppritz. La Figura 9 muestra la sección sísmica (stack) del dato observado. Para cada gather, con fines puramente estadísticos, se realizaron 50 inversiones en cada caso con M=25.
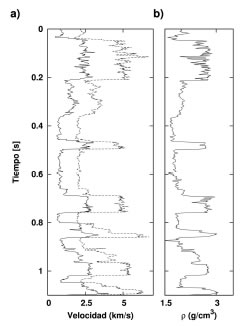
Figura 7. Modelo de velocidades. a) Línea punteada, velocidad de la onda P. Línea contínua, velocidad de la onda S, b) densidad.
Figure 7. Velocity model. a) dashed line, P-wave velocity. Continuous line, S-wave velocity, b) density.
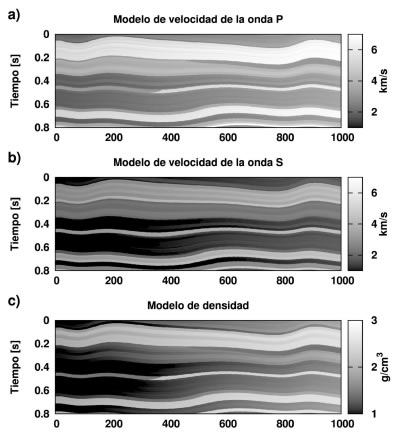
Figura 8. Modelo de velocidades 2D. a) Velocidad de la onda P, b) velocidad de la onda S, c) densidad.
Figure 8. 2D velocity model. a) P-wave velocity, b) s-wave velocity, c) density.
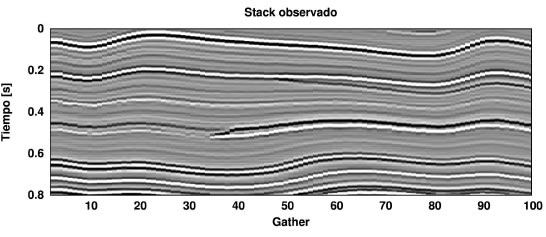
Figura 9. Sección sísmica (stack) del dato sintético 2D.
Figure 9. Stack section of the 2D synthetic data
La Figura 10 muestra el Intercept calculado a partir del modelo de la Figura 8, y el estimado luego de promediar las 50 inversiónes. Análogamente, la Figura 11 muestra los resultados para el Gradient. Se aprecia que el método ofrece buenos resultados, conservando la continuidad lateral e invirtiendo satisfactoriamente los parámetros de la aproximación de Shuey.
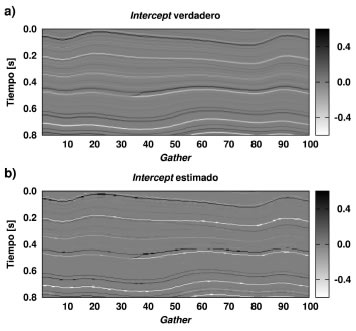
Figura 10. a) Intercept verdadero del dato sintético 2D, b) Intercept estimado.
Figure 10. a) Actual Intercept from 2D synthetic data, b) estimated Intercept.

Figura 11. a) Gradient verdadero del dato sintético 2D, b) Gradient estimado.
Figure 11. a) Actual Gradient from 2D synthetic data, b) estimated Gradient.
En la Figura 12 se observa con mayor detalle el resultado correspondiente al Intercept seleccionando una ventana de 0.3 s por 20 gathers. Allí queda en evidencia la capacidad del método para resolver reflectores cercanos. Notar que la diferencia temporal entre los reflectores que forman el par ubicado a los 0.05 s (señalados en las Figuras 12a y 12b) se encuentra en el orden del espesor de tuning, que para el caso de los datos utilizados es aproximadamente 11 ms. Lo mismo ocurre con los reflectores que forman el par ubicado a los 0.2 s (señalados en las Figuras 12a y 12b). El espesor de tuning es el mínimo espesor que debe poseer una capa para que los reflectores en el tope y la base se resuelvan como dos eventos separados. Para un espesor menor al del tuning las reflecciones comienzan a verse como un sólo evento. Para el caso de una ondícula de Ricker de frecuencia central 0 fel espesor de tuning se puede expresar en unidades de tiempo como (Chung y Lawton, 1995)
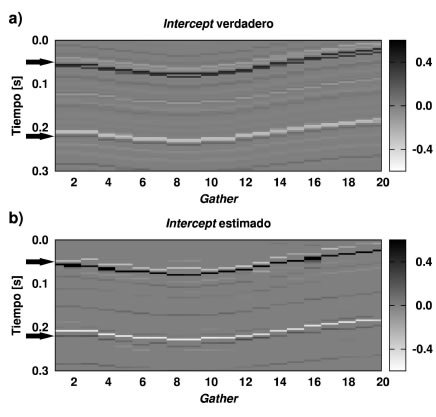
Figura 12. a) Detalle del Intercept verdadero del dato sintético 2D, b) detalle del Intercept estimado.
Figure 12. a) Zoom on the actual Intercept from 2D synthetic data, b) zoom on the estimated Intercept.
![]()
En este caso, con 35 0 f = Hz se obtiene un valor para el espesor de tuning de aproximadamente 11 ms, lo que equivale aproximadamente a 3 muestras.
Datos de campo
Los datos de campo consisten en 61 gathers ordenados por Common Depth Point (CDP) y corregidos por NMO. El intervalo de muestreo es de 4 ms. Cada CDP-gather fue convertido a angle-gather utilizando la información de velocidades obtenidas de un pozo cercano. Al igual que con los datos sintéticos, para la inversión se utilizó la aproximación de Shuey de dos términos. Asimismo se seleccionó M=30.
Para cada gather se obtuvo un arreglo que contiene las estimaciones de los coeficientes de la aproximación de Shuey. Una vez invertidos, se reconstruyó el gather y se calculó el stack correspondiente. Como en el ejemplo con datos sintéticos, y por razones estadísticas, se realizaron 50 inversiones y se tomó la media como solución final. La Figura 13 muestra, respectivamente, el stack del dato observado, el stack estimado luego de la inversión y el residuo correspondiente. Se observa que los datos estimados son muy similares a los datos observados. Los reflectores más importantes han sido encontrados y se consiguió un buen ajuste, siendo los residuos muy pequeños.
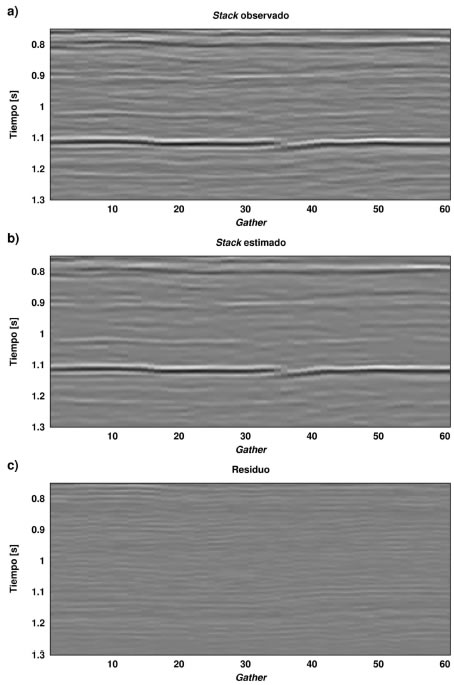
Figura 13. a) Sección sísmica (stack) del dato de campo, b) Sección sísmica (stack) estimada del dato de campo, c) residuo.
Figure 13. a) Stack section of the field data, b) estimated stack section of the field data, c) residual.
Las imágenes de alta resolución del Intercept y del Gradient pueden observarse en las Figuras 14a y 15a, respectivamente, en tanto que las Figuras 14b y 15b muestran las correspondientes desviaciones estándar. Se puede observar que todos los reflectores más significativos fueron resueltos satisfactoriamente. Nótese además que se obtiene una continuidad lateral razonable, lo que demuestra la consistencia del método de inversión, a pesar de que no fue impuesta ninguna condición en este sentido durante la inversión y de que la calidad de los datos utilizados no contribuye a resaltar este comportamiento. Esto último se pone de manifiesto en los valores relativamente altos del desvío estándar de las soluciones.
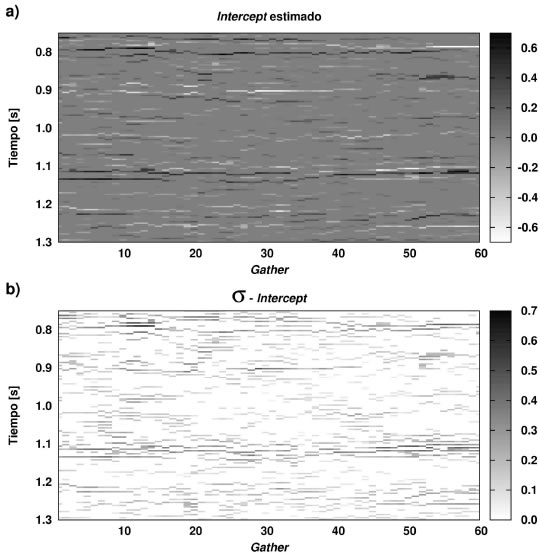
Figura 14. Intercept estimado del dato de campo, b) desvío estándar del Intercept.
Figure 14. Estimated Intercept from the field data, b) standard deviation of the Intercept.

Figura 15. Gradient estimado del dato de campo, b) desvío estándar del Gradient.
Figure 15. Estimated Gradient from the field data, b) standard deviation of the Gradient.
CONCLUSIONES
Presentamos un método de inversión sparse-spike para obtener atributos AVO/AVA de alta resolución a partir de datos prestack. El metodo está basado en buscar el menor número de reflectores que honren el dato observado. Contrariamente a otros métodos que también buscan soluciones de tipo sparse, y donde el número de incógnitas coincide con el número de muestras del dato sísmico, en la estrategia propuesta el número de incógnitas es mucho menor. Como consecuencia, las matrices utilizadas en los cálculos son de dimensión reducida y la inversión es relativamente económica en términos de costo computacional, aún cuando la inversión se realiza utilizando SA. La ubicación en tiempo de los reflectores lleva a un problema de optimización no lineal que se resolvió utilizando VFSA. El uso de este método de optimización global estocástico nos permitió obtener conjuntos de soluciones que ajustan al dato, por lo que la incertidumbre de las mismas pudo ser estimada. La respuesta AVO/AVA se estimó resolviendo, en cada iteración del annealing, el problema de mínimos cuadrados que ajusta los parámetros Intercept y Gradient que definen la aproximación de Shuey al dato observado. No obstante, la extensión del procedimiento a otras aproximaciones es inmediata. El método fue probado sobre datos sintéticos y datos reales. Sobre datos sintéticos 1D el método demostró ser robusto en presencia de ruido aleatorio, incertidumbre en los parámetros que definen a la ondícula y en el número de reflectores. Se obtuvieron muy buenos resultados en todas las magnitudes invertidas, estimándose con precisión la ubicación en tiempo de los reflectores y la respuesta AVO/AVA de los mismos. La frecuencia central y la rotación de fase de la ondícula de Ricker fueron incorporadas como incógnitas adicionales de la inversión pudiendo éstas estimarse con éxito. Los pequeños valores de las desviaciones estándar de las magnitudes invertidas resaltan la consistencia de las soluciones. Se demostró que el número de reflectores a buscar durante la inversión no es crítico. Las pruebas sobre datos sintéticos 2D demostraron la capacidad del método para resolver reflectores cercanos y para obtener soluciones del tipo sparse-spike a partir de datos que no muestran, a priori, esa clase de comportamiento. También se observó la capacidad de obtener soluciones con buena continuidad lateral a pesar de que no se impuso ninguna clase de condición en este sentido durante la inversión. Sobre datos de campo el método mostró buen comportamiento a pesar de que la calidad de los datos utilizados no era la óptima. Los reflectores más importantes fueron encontrados y se obtuvieron imágenes de alta resolución del Intercept y del Gradient con buena continuidad lateral que honran al dato observado.
Agradecimientos: Agradecemos a Mauricio D. Sacchi por sus valiosos comentarios. Este trabajo fue parcialmente financiado por la Agencia Nacional de Promoción Científica y Tecnológica (PICT-2010-2129) y por CONICET. Agradecemos también el apoyo de Dataseismic Geophysical Services.
REFERENCIAS
1. Alemie, W.M., 2010. Regularization of the AVO inverse problem by means of a multivariate Cauchy probability distribution. M.S. thesis, The University of British Columbia. [ Links ]
2. Alemie, W.M. y M.D. Sacchi, 2011. High-resolution three-term AVO inversion by means of a Trivariate Cauchy probability distribution. Geophysics, 76, 43-55 [ Links ]
3. Aki, K.I. y P.G. Richards, 1980. Quantitative seismology. W. H. Freeman and Co. [ Links ]
4. Bortfeld, R., 1961. Approximation to the reflection and transmission coefficients of plane longitudinal and transverse waves. Geophys. Prosp., 9, 485-503. [ Links ]
5. Castagna, J.P., H.W. Swan y D.J. Foster, 1998. Framework for AVO Gradient and Intercept interpretation. Geophysics, 63, 948-956 [ Links ]
6. Chung, H. y D. Lawton, 1995. Frequency characteristics of seismic reflections from thin beds. Canadian Journal of Exploration Geophysicists, 31, 32-37. [ Links ]
7. Downton, J.E. y R.L. Lines, 2003. High-resolution AVO analysis before NMO. 73rd Annual International Meeting, SEG, Expanded Abstracts, 219-222. [ Links ]
8. Fatti, J.L., G.C. Smith, P.J. Vail, P.J. Strauss, y P.R. Levitt, 1994. Detection of gas in sandstone reservoirs using AVO analysis: A 3-D seismic case history using the Geostack technique. Geophysics 59, 1362-1376. [ Links ]
9. Ingber, L., 1989. Very fast simulated re-annealing. Journal of Mathematical Computation and Modelling, 12, 967- 973. [ Links ]
10. Kirkpatrick, S., C.D. Gellat y M.P. Vecchi, 1983. Optimization by simulated annealing. Science, 671-680. [ Links ]
11. Metropolis, N., A.W. Rosenbluth M.N. Rosenbluth, A.H. Teller y E. Teller, 1953. Equation of state calculations by fast computing machines. J. Chem. Phys. 21 (6), 1087-1092. [ Links ]
12. Pérez, D.O., y D.R. Velis, 2011a. Sparse-spike AVO/AVA attributes from seismic data. 81st Annual International Meeting, SEG, Expanded Abstracts, 18-23. [ Links ]
13. Pérez, D.O., y D.R. Velis, 2011b. Atributos AVO/AVA de alta resolución a partir de datos prestack. VIII Congreso de Exploración y Desarrollo de Hidrocarburos, En Integración: acercando la ondícula al trépano, 145-154. [ Links ]
14. Misra, S. y M.D. Sacchi, 2008. Global optimization with model-space preconditioning: Application to AVO inversion. Geophysics, 73, 71-82. [ Links ]
15. Shuey, R.T., 1985. A simplification of the Zoeppritz equations. Geophysiscs, 50, 609-614. [ Links ]
16. Smith, G.C. and P.M. Gidlow, 1987. Weighted stacking for rock property estimation and detection of gas. Geophys. Prosp., 35, 993-1014. [ Links ]
17. Velis, D.R., 2008. Stochastic sparse-spike deconvolution. Geophysics, 73, 1-9. [ Links ]
18. Verm, R. y F. Hilterman, 1995. Lithology color-coded seismic sections: The calibration of AVO crossplotting to rock properties. The Leading Edge, 14, 847-853. [ Links ]
19. Yilmaz, Ö., 2001. Seismic data analysis: processing, inversion and interpretation of seismic data. Society of Exploration Geophysicists. [ Links ]
20. Zoeppritz, K., 1919. Über Reflexion and Durchgang seismischer Wellen durch Unstetigkeits-flä;chen. Gott. Nachr. Math. Phys. Kl., 66-84. [ Links ]
Recibido: 1-3-12
Aceptado: 29-5-12

