











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. Introdução
A melhoria da qualidade de metadados, ou seja, o seu enriquecimento a partir de elementos semânticos e contextuais, tem sido um dos principais esforços nas agendas de trabalho de iniciativas que agregam e compartilham dados do patrimônio cultural. Com propostas de modelos colaborativos de representação da informação, dois projetos de destaque, um internacional e outro nacional, contribuem para a produção significativa de metadados no contexto do patrimônio cultural, sobretudo a partir da folksonomia.
O projeto CrowdHeritage, criado no âmbito dos serviços da Europeana - plataforma agregadora de dados do patrimônio cultural em nível internacional1 - foi proposto visando envolver as comunidades de usuários no enriquecimento dos metadados das diversas coleções digitais do patrimônio cultural europeu. Por meio de campanhas de crowdsourcing, a plataforma aberta cria um ambiente para enriquecer representações do conteúdo cultural, tanto pela validação das anotações produzidas automaticamente por ferramentas baseadas em Inteligência Artificial, como de modo manual a partir de anotações compostas, principalmente, por comentários e etiquetas adicionados por usuários.
Já o projeto brasileiro, Arquigrafia, em uma escala menor em comparação à Europeana, buscou se desenvolver nessa mesma esteira, partilhando as coleções iconográficas digitalizadas da arquitetura e espaços urbanos brasileiros do Setor de Materiais Iconográficos da Biblioteca da Faculdade de Arquitetura e Urbanismo da Universidade de São Paulo (FAU/USP) em um ambiente colaborativo Web, permitindo que seus usuários contribuam para a representação de conteúdos pertinentes ao tema.
Apesar da diferença de escala e escopo, em ambos os casos é possível identificar a preocupação com o emprego de modelos colaborativos de representação da informação na plataforma para o trabalho de enriquecimento de metadados, ficando o questionamento de como tais projetos realizam esses processos e quais são as possibilidades e os desafios que enfrentam com relação à folksonomia. Cunhado em 2004 por Thomas Vander Wal, o termo folksonomia resulta da junção das palavras “folk” e “taxonomy”, que significam respectivamente, “povo” ou “grupo de pessoas” e “ciência ou técnica de classificação” (Amstel, 2007). Dessa maneira, a folksonomia é definida como o “[...] resultado do processo de etiquetagem livre (atribuição de etiquetas ou palavras-chave) realizada pelos usuários mediante o emprego de termos provenientes da linguagem natural [...]” (Corrêa & Santos, 2018, p. 29).
Assim, o objetivo do artigo é discutir as práticas colaborativas de representação de recursos informacionais nas plataformas Arquigrafia e CrowdHeritage, tendo em vista as potencialidades da folksonomia para a representação da informação e do conhecimento.
Os esforços em produzir metadados que melhor representem os objetos informacionais são uma preocupação clássica das instituições que lidam com os registros do conhecimento humano, como as bibliotecas, os arquivos, os museus e entre outras. A sinergia de suas coleções digitais, comumente denominadas coleções GLAM (do acrônimo Galleries, Libraries, Archives and Museums), é aproveitada em produtos e serviços no domínio do patrimônio cultural, sendo seus dados amplamente disponibilizados em plataformas ou portais da Web.
Visto os benefícios do compartilhamento em rede, as iniciativas GLAM deparam-se com novas oportunidades e desafios que surgem ao buscar tirar proveito de instrumentos para o enriquecimento semântico de seus dados. Entre esses instrumentos estão aqueles que agregam as potencialidades da folksonomia.
Entendidos como sistemas híbridos de organização do conhecimento, os instrumentos que usam a etiquetagem livre com o suporte dos formalismos e métodos utilizados na construção de instrumentos de controle terminológicos, como a ontologia, taxonomia, o tesauro (Santos & Albuquerque, 2021), passam a ocupar um espaço importante nos fluxos de trabalho das plataformas digitais que agregam e compartilham dados do patrimônio cultural, juntamente com ferramentas de enriquecimento automático de metadados baseadas em técnicas e ferramentas de Inteligência Artificial (Kaldeli, Menis-Mastromichalakis, Bekiaris, Ralli, Tzouvaras & Stamou, 2021).
Desse modo, os ambientes que fazem uso do crowdsourcing, ou seja, projetos de participação do público para um propósito específico (Ridge, 2014), mostram-se um campo fértil para análise e discussões sobre as possibilidades e os desafios de implementaçãodos modelos colaborativos de representação da informação no emprego da folksonomia, uma vez que o crowdsourcing é o meio em que esses modelos operam.
Ainda, a própria folksonomia, por ser constituída de palavras-chaves definidas ou selecionadas pelos usuários, apresenta-se como uma contribuição fundamental para a garantia cultural2 e para o domínio do patrimônio cultural, que só tem suas atividades efetivadas com abordagens que considerem fatores e perspectivas socioculturais.
2. Modelos colaborativos de representação da informação e os sistemas híbridos de organização do conhecimento
No domínio do patrimônio cultural, a busca pela colaboração não é novidade. A preocupação em aprimorar o atendimento à comunidade interessada, ou seja, seus públicos e usuários tem sido foco das diversas discussões e estudos que caracterizam o chamado paradigma pós-custodial cujo fundamento está na perspectiva social e na integração de conhecimentos para a promoção do amplo acesso à informação (Silva & Ribeiro, 2002).
Nesse sentido, é possível observar que o próprio desenvolvimento da Ciência da Informação, perspectiva na qual este trabalho está ancorado, caminhou no sentido da passagem de um paradigma físico (inicial) e cognitivo para posteriormente um paradigma social, com referência ao período de transição do paradigma custodial para o pós-custodial (Miranda, 2010). Essa passagem marca também a distinção entre o paradigma do sistema e o paradigma do usuário, conhecida como a virada cognitivista, na qual o foco da área é deslocado das “coisas” para os sujeitos (Renault, 2007).
É nessa passagem que os modelos colaborativos de representação da informação têm seu afloramento nos sistemas em rede, sendo impulsionados pelo desenvolvimento do que é conhecido como fase social da Web, a qual se caracteriza pela possibilidade de maior interação entre as pessoas e a participação ativa dos usuários. Rompendo com o modelo inicial da Web, cujas formas de representar e recuperar a informação eram baseadas em modelos sintáticos, isto é, com foco apenas nas estruturas dos dados, a segunda fase da Web trouxe a possibilidade de os usuários interagirem com os conteúdos produzidos e participarem dessa produção, o que ocasionou o aumento do volume de dados e a consequente limitação da capacidade de encontrar informações (Vidotti, Coneglian, Roa-Martínez, Vechiato & Segundo 2019).
Tal como observa Miranda (2010, p. 17), “[...] os avanços das tecnologias estão aliados aos estudos sobre as tendências de comportamento da sociedade, com a finalidade de se aproximar da realidade social do usuário”. Logo, a aplicação de métodos e instrumentos que resultam em uma maior capacidade de encontrar informações e atender às demandas se tornou fundamental. Representar a informação em rede implicava em mais do que descrever as relações estruturais. Era necessário identificar as relações semânticas entre os conteúdos, sobretudo, fazer com que os sistemas computacionais entendessem essas relações para serem mais assertivos na busca e recuperação da informação.
Assim, o desenvolvimento das tecnologias que sustentam a Web caminhou na direção de ampliar o processamento de dados legíveis para máquinas, permitindo aumentar o nível de automação, caracterizando a fase da Web que é denominada como Semântica. Tais esforços conduziram a implementação e o aprimoramento de soluções tecnológicas centradas em ontologias e linguagens formais padronizadas (Hitzler, 2021) de modo a fornecer maior definição semântica, utilizando, para isso, um maior volume de metadados padronizados. Contudo, observou-se que somente o aumento na quantidade de elementos representativos não tornavam a Web mais significativa, sendo necessário ampliar a qualidade desses metadados.
É nesse sentido que os modelos colaborativos ganham força, permitindo ampliar e aprimorar a capacidade de organização e representação dos conteúdos informacionais, mais especificamente no que se refere à atividade de indexação, operação que passa a coexistir com formas de descrição que não adotam regras formais de controle de vocabulário (Santos, 2016; Tammaro & Salarelli, 2008). Dessa forma, os modelos colaborativos de indexação são compreendidos por Santos (2016) como modelos que delineiam práticas colaborativas de indexação em diferentes cardinalidades a serem executadas pelos usuários, servindo como referência para o desenvolvimento de sistemas. Esses modelos podem ser aplicados ou aperfeiçoados em diferentes ambientes digitais.
Nessa perspectiva, a participação dos usuários na escolha dos descritores do conteúdo que eles próprios criam e/ou consomem, passou a ser um tema bastante estudado como processos de indexação e classificação social, cujas características afastam-se das formas hierárquicas e centralizadas de categorização e indexação tradicionais. É nesse contexto que o termo “folksonomia” é proposto para designar o resultado da representação feita pelo usuário na etiquetagem livre de recursos informacionais na Web (Vander Wal, 2005).
Apesar das diversas formas de interpretação e algumas críticas que vieram com a popularização do termo folksonomia (Corrêa & Santos, 2018; Santos, 2016), a ideia principal é a de que ela consiste em uma manifestação de linguagens criadas e compartilhadas pelos usuários que ampliam a capacidade de representação dos aspectos semânticos e sociais inerentes à informação, o que, consequentemente, enriquece esse processo.
Logo, as vantagens de utilizar metadados, ou seja, elementos representativos gerados pelos usuários, para aperfeiçoar os instrumentos de controle terminológico, tornaram-se mais evidentes aos profissionais da informação, que passaram a considerar estruturas de representação mais flexíveis e a possibilidade da folksonomia como ferramenta auxiliar aos instrumentos de controle terminológico (Viera & Garrido, 2011).
De tal modo, propostas de instrumentos que agregam a folksonomia às estruturas de representação de conhecimento, como as ontologias, taxonomias e os tesauros, ficaram mais comuns para auxiliar na troca de conhecimentos em um ambiente Web cada vez mais interconectado, lógico e pragmático, resultando em propostas de hibridização de modelos e sistemas de organização do conhecimento.
Exemplos de instrumentos que aproveitam ambas as potencialidades da linguagem natural e da linguagem controlada podem ser vistos na literatura, como o Tag-Ontology, uma ontologia dedicada a formalizar a ação de etiquetagem a partir da relação entre os elementos, objeto (item informacional etiquetado); as etiquetas utilizadas na marcação; o usuário que realizou a etiquetagem; e o domínio no qual a etiquetagem é realizada (Gruber, 2005). Outro exemplo é o Taxo-Folk, um algoritmo projetado para integrar a folksonomia com uma taxonomia por meio de técnicas de mineração de dados (Kiu & Tsui, 2011).
No que tange ao patrimônio cultural, nas últimas décadas, as tecnologias disponíveis oportunizaram a criação de uma série de iniciativas que reúnem esforços, tanto em nível organizacional e regional, como também em nível nacional e internacional para agregar, facilitar e ampliar o acesso a conteúdo cultural digital. Como explica Kaldeli e seus colaboradores (2021, p. 2, tradução nossa):
Essas iniciativas visam, por um lado, agilizar o processo de agregação e tornar mais fácil para as instituições do patrimônio cultural preparar e compartilhar conteúdo de alta qualidade e, por outro lado, envolver usuários de diferentes públicos - de educadores e inventivos, a pesquisadores e o público em geral - por meio de uma série de serviços de valor agregado que tornam o conteúdo prontamente disponível para navegação, pesquisa, estudo e reutilização.
Entre essas iniciativas, a Europeana destaca-se pelo pioneirismo e pela vasta documentação que disponibiliza acerca de seus serviços e ferramentas, bem como pelas constantes melhorias, sobretudo, em relação ao enriquecimento da qualidade dos metadados. Figurando como uma das principais prioridades dos planos estratégicos da Europeana, o enriquecimento da qualidade dos metadados dos objetos digitais é foco de diversos projetos lançados nos últimos anos. O desenvolvimento desses projetos tem se beneficiado da união dos avanços em tecnologias de inteligência artificial com a inteligência humana, mais especificamente no emprego do “poder da multidão”, processo conhecido como crowdsourcing, cujo objetivo é “[...] aproveitar a inteligência de um grande grupo heterogêneo de pessoas para resolver problemas em escalas e taxas que nenhum indivíduo sozinho pode [...]” (Kaldeli et al., 2021, p. 3, tradução nossa).
Assim, a ideia é unir os resultados do enriquecimento acionados por máquina à ação da inteligência humana coletiva por meio campanhas de crowdsourcing de modo a criar um ambiente colaborativo para a produção significativa de metadados semânticos que tornam o conteúdo mais rico e significativo para quem o busca e utiliza.
3. Crowdsourcing e a folksonomia
O termo ou expressão “crowdsourcing” foi cunhado para designar um modelo ou processo de obtenção de serviços que se baseia na colaboração. Configura-se como uma palavra-valise da língua inglesa composta por duas outras: “crowd” e “outsourcing”, que respectivamente significam “multidão” e “terceirização”. O termo foi cunhado em 2005 por Jeff Howe e Mark Robinson e popularizado por Howe em uma postagem de blog em junho de 2006 com a seguinte definição:
[...] Crowdsourcing representa o ato de uma empresa ou instituição designar uma função antes desempenhada por funcionários e terceirizá-la para uma rede indefinida (e geralmente grande) de pessoas na forma de uma chamada aberta. (Howe, 2006, não paginado, tradução nossa).
Nesse sentido, entende-se que crowdsourcing é uma atividade participativa que ocorre em plataformas interativas on-line com foco na colaboração de fontes externas e na participação social de um grupo variado de pessoas com diferentes graus de conhecimentos. É, portanto, um modelo de colaboração com características amplas e heterogêneas que faz uso das potencialidades das tecnologias disponíveis, visando um objetivo em comum. Como explica Ellis (2014), tais modelos de colaboração sempre estiveram presentes na sociedade, o que mudou foi a possibilidade de incluir a multidão conectada em rede pela internet, facilitando e ampliando a troca de informações e conhecimentos.
Diferentes tipologias de crowdsourcing podem ser encontradas na literatura em função de suas múltiplas formas de aplicação (Fernandes, 2012). Dentre as tipologias mais utilizadas, destaca-se a original definida por Howe (2008) que se apresenta na forma de quatro categorias básicas de aplicação: crowd wisdom, com referência à inteligência coletiva; crowd creation, com a ideia de energia criativa da multidão; crowd voting, para se referir à opinião ou julgamento por meio de votação ou classificação; e, por último, crowdfunding, para designar o ato de financiamento coletivo.
Outra tipologia bastante abordada na literatura é a de Brabham (2012), que apresenta quatro tipos baseados em problemas de abordagens de crowdsourcing. A primeira categoria é a Knowledge Discovery and Management, ou seja, envolve a atividade de descoberta de conhecimento e gestão que é designada a um grupo de pessoas para que encontrem e reúnam determinadas informações. A segunda é a denominada The Broadcast Search, que envolve a mobilização de um grupo com o conhecimento necessário para resolver um problema específico e chegar a uma solução objetiva. A terceira categoria é a Peer-vetted creative production, que consiste em uma abordagem para a concepção e seleção de ideias criativas, nas quais as soluções são em geral subjetivas, relacionadas às preferências dos consumidores ou dependentes do apoio público. E, por último, a categoria Distributed Human Intelligence Tasking que se refere à mobilização de um grupo para executar tarefas que necessitam de julgamento e inteligência humana, como no caso da análise de grandes quantidades de informação em que o raciocínio humano é mais útil que a análise por computador (Fernandes, 2012).
Independente da tipologia, o que se destaca nos estudos sobre o crowdsourcing é o potencial das informações e dos conhecimentos humanos que podem ser aproveitados em função da comunidade interessada conectada em rede, especialmente, no que tange à inclusão social e à democratização da produção e compartilhamento do conteúdo. Esse processo de aproveitamento de informações e conhecimentos dos usuários em ambientes em rede desenvolve-se principalmente a partir do fenômeno da Web 2.0, mais especificamente, em conjunto com os sistemas de marcação e etiquetagem social. A inclusão de marcadores ou etiquetas (tags) por usuários com linguagem natural é comumente conhecida, entre outras denominações, como folksonomia.
O emprego da folksonomia em ambientes digitais colaborativos de patrimônio cultural resultou em grandes oportunidades de aprimorar o modo como o conteúdo é vivenciado pelos usuários, aproximando-os muito mais dos processos realizados sobre as coleções que eles próprios fazem uso. Como discute Mai (2011), ao permitir a pluralidade de pontos de vista e opiniões, a inclusão de termos derivados da percepção dos usuários em relação aos objetos informacionais concebem uma nova ordem no cenário da organização e representação do conhecimento. Diferente dos vocabulários controlados que consistem em linguagens construídas com formalismo de acordo com a interpretação das necessidades dos usuários, a folksonomia deriva da livre etiquetagem sem o envolvimento de profissionais, ou seja, de acordo com a interpretação dos próprios usuários por pertencerem ao seu universo semântico.
Isso resulta em um alto grau de liberdade para a categorização dos recursos informacionais dando o caráter de descentralização e subjetividade aos processos de representação dos ambientes colaborativos. Dentre as características básicas inerentes à folksonomia, está a simplicidade no processo de representação dos recursos, a falta de estrutura e hierarquia de conceitos dos termos elencados pelos usuários, o que os tornam mais flexíveis e possibilitam a navegação por etiquetas relacionadas, bem como a coexistência de diversos pontos de vista dos usuários a respeito de um determinado assunto, uma vez que as tags refletem a dinamicidade da língua e da cultura (González, 2006). Assim sendo, o que pode ser vantagem resultante da etiquetagem livre apresenta desafios para a efetividade da recuperação da informação. Isso ocorre, sobretudo, porque a falta de controle sobre linguagem de representação pode gerar, entre outras implicações, inconsistências terminológicas no domínio e entre os domínios do conhecimento, bem como entre expressões regionais e idiomas, além da ocorrência de erros ortográficos e de digitação (Catarino & Baptista, 2009; Santos, 2016).
Sendo assim, a hibridização, isto é, a coexistência dos vocabulários controlados e da folksonomia para a representação do conhecimento em um dado domínio (Santos & Albuquerque, 2021) tem se mostrado uma solução promissora para aproveitar tanto as vantagens do formalismo e dos métodos de construção de instrumentos de controle terminológicos, quanto das múltiplas perspectivas e consensos semânticos gerados a partir da folksonomia em sistemas colaborativos.
Paralelamente, no contexto dos sistemas colaborativos, também surge a ideia de um processo de apoio ao usuário no momento da escolha de tags para fins de representação e recuperação de recursos, denominado folksonomia assistida. Santarém Segundo (2010) explica que a folksonomia assistida permite auxiliar o usuário na descrição do assunto do recurso informacional, visando a consistência das tags escolhidas em relação ao domínio do conhecimento do qual faz parte. Esse processo de auxílio ocorre quando o usuário, ao inserir tags, é apresentado um conjunto de sugestões de termos relacionados já cadastrados previamente no sistema. Esses termos, por sua vez, fazem parte de uma estrutura de representação do conhecimento, podendo ser um tesauro, uma ontologia ou taxonomia, que auxiliará na escolha de descritores mais adequados com base no relacionamento dos termos do domínio.
Nesse panorama, com vistas a aproveitar a inteligência coletiva para a representação da informação e contribuir ainda mais para a troca de conhecimentos no ambiente Web, diversas formas de crowdsourcing no domínio do patrimônio cultural têm sido criadas, entre elas, as que propõem a participação da inteligência coletiva para a representação da informação. Oomen & Aroyo (2011) sistematizam, tal como apresentado no Quadro 1, seis tipos principais de iniciativas de crowdsourcing que podem ser encontradas no domínio do patrimônio cultural.
Quadro 1 Tipos de iniciativas de crowdsourcing do patrimônio cultural.

Fonte: baseado em Oomen & Aroyo (2011).
A partir de campanhas de crowdsourcing, é possível criar um canal interativo baseado em sistemas colaborativos para que os usuários se sintam encorajados a contribuir com informações.
Dentre as principais formas de colaboração em rede, os modelos de anotação têm sido bastante utilizados.3 A definição tradicional de “anotação” remete ao ato de adicionar notas explicativas e informações escritas à mão nas margens das páginas de documentos ou livros. Com o fenômeno da Web, as anotações popularizaram-se como informações extras adicionadas a um item informacional sem modificá-lo, principalmente de modo automatizado, com a finalidade de explicitar sua interpretação (Hunter, 2009). Sendo assim, os modelos de anotação podem ser entendidos como uma forma computacional de adicionar significado a um recurso informacional digital e tornar a informação explícita, o que ocorre por meio da atribuição de tags, demais metadados e ontologias.
Em ambientes colaborativos, as anotações podem ser feitas por usuários de modo complementar às anotações automatizadas, gerando comentários, citações, marcações semânticas e geográficas, bem como reutilizando vocabulários de modo mais significativo para suas demandas. Dessa forma, por meio das campanhas de crowdsourcing, é possível aproveitar anotações distribuídas e integrar os metadados gerados pela comunidade interessada, ou seja, pelos usuários, juntamente com os metadados institucionais autorizados de forma a fornecer uma abordagem híbrida na representação do conteúdo (Hunter, 2009). Além disso, dependendo do tipo de conteúdo e se há representações incompletas, é possível criar formas de validar os metadados existentes ou sugerir opções para escolha, processos que em geral ocorrem por meio de votação ou classificação (Crowdheritage, 2021; Kaldeli et al., 2021).
Para esse processo, as ferramentas automáticas de criação de metadados contribuem sobremaneira, reduzindo tempo e os recursos gastos. Porém, estudos demonstram que métodos puramente automáticos geram limitações técnicas e metodológicas que incidem na eficácia, escalabilidade e potencial de reutilização dos metadados (Kaldeli et al., 2021). Portanto, a união entre os serviços de análise automatizada e extração de dados combinados aos serviços de crowdsourcing, que fazem uso da folksonomia, principalmente assistida, tem trazido grandes resultados na obtenção de metadados de maior qualidade.
4. Metodologia
Com base em seu objetivo geral, esta pesquisa caracteriza-se como qualitativa, exploratória-descritiva, bibliográfica e documental, empregando como método a análise de conteúdo, cujas técnicas e os procedimentos serviram de base para a coleta e análise de dados. Para a Bardin (2011), a análise de conteúdo objetiva investigar o que foi dito em um meio de comunicação, construindo e apresentando sistematicamente as concepções em torno de um objeto de estudo, definido aqui como as aplicações da folksonomia nos projetos CrowdHeritage e Arquigrafia.
Logo, na primeira fase Análise de Conteúdo indicada pelo autor, denominada Pré-análise, ocorre o procedimento inicial de organização do material, na qual se dá a escolha, a formulação de critérios e a preparação material para análise que fundamentará a interpretação, passos estes, delineados a partir dos objetivos do estudo; em sequência, a fase de Exploração do material consiste em sistematizar e aplicar as decisões definidas na primeira fase, realizando a leitura dos materiais selecionados, assim como a sistematização das relações existentes entre os elementos encontrados a partir de categorias de análise, definidas neste estudo a posteriori, isto é, com base na leitura do material selecionado para compor o corpus de análise na fase de Exploração, quanto aos modelos colaborativos de representação da informação. Por último, na fase de Tratamento dos dados, inferência e interpretação, os dados e informações coletados são arranjados para a apresentação e validados à luz da fundamentação teórica, possibilitando fazer inferências e interpretações para o desenvolvimento dos resultados e das discussões para a apresentação.
Para compor o material de análise recorre-se à literatura científica que discorre sobre os temas no período de 2000 a 2021, considerando os termos de busca nos idiomas português e inglês - “folksonomia”; “crowdsourcing”; “CrowdHeritage”; “Arquigrafia", no âmbito nacional e internacional, no período de janeiro a fevereiro de 2022 - disponível por intermédio da Base de Dados em Ciência da Informação (BRAPCI), da Dimensions, bem como do Portal de Periódicos CAPES, o qual inclui as bases internacionais Web of Science, Scielo . Scopus.
A escolha das produções científicas foi delimitada aos materiais publicados que atendessem aos critérios de pertinência aos temas definidos e estivessem disponíveis em acesso livre. A fim de complementar o corpus de análise, considera-se também os documentos primários disponibilizados pela CrowdHeritage e Arquigrafia, como os relatórios que descrevem respectivamente seus projetos e implementações.
O universo da pesquisa, portanto, é composto pelos dados e informações coletadas a partir da análise das interfaces das próprias plataformas quanto aos seus aspectos e funcionalidades, incluindo os documentos primários disponibilizados acerca de seus próprios projetos e as publicações científicas que discorrem sobre seus modelos colaborativos de representação da informação.

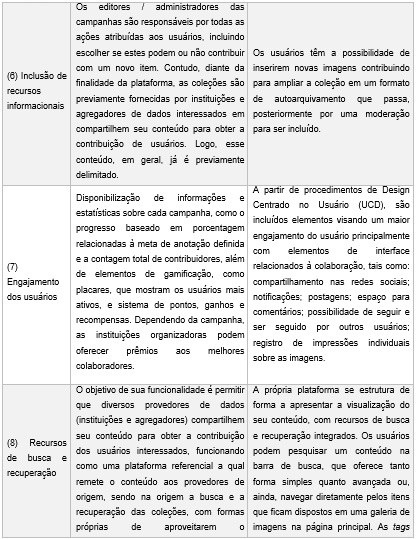
Após a análise de conteúdo referente ao corpus da pesquisa, foram elencadas nove categorias de análise pertinentes à proposta, identificadas e nomeadas de acordo com a observação dos aspectos e funcionalidades dos modelos colaborativos de representação da informação presentes nas interfaces das plataformas de ambos os projetos a luz da fundamentação teórica. São elas: (1) Domínio de aplicação; (2) Formas de contribuição; (3) Tipos de representação; (4) Sugestão de termos e recursos de padronização; (5) Revisão da contribuição; (6) Inclusão de recursos informacionais; (7) Engajamento dos usuários; (8) Recursos de busca e recuperação; (9) Trabalhos futuros.
Desse modo, procedeu-se a sistematização das relações existentes entre os fundamentos dos materiais selecionados, oportunizando a comparação entre suas funcionalidades e a discussão almejada.
5. Análise e discussão dos resultados
A análise comparativa foi desenvolvida com base no conteúdo disponibilizado pelas plataformas e por publicações científicas que descrevem e discutem os projetos. Sendo assim, buscou-se identificar como cada uma propõe suas práticas colaborativas de representação de objetos informacionais.
5.1 CrowdHeritage
A plataforma CrowdHeritage foi desenvolvida no âmbito do projeto da Europeana Generic Services pela Universidade Técnica Nacional de Atenas em colaboração com a European Fashion Heritage Association, a MICHAEL Culture Association e o Ministério da Cultura da França, para criar um ecossistema colaborativo com base nas potencialidades de um serviço de crowdsourcing (CrowdHeritage Platform, 2020; Crowdheritage, 2021). Desenvolvida entre setembro de 2018 a fevereiro de 2020, a plataforma é agora uma ferramenta dos serviços da Europeana para apoiar profissionais e instituições do patrimônio cultural na interação com os dados.
Como uma plataforma de código aberto, a CrowdHeritage conecta-se à plataforma principal de serviços da Europeana por meio um conjunto de Application Programming Interface (API)4 especificados para cada função, como as APIs Europeana Search, Record, Annotations e Entity, bem como as demais APIs disponibilizadas por outras iniciativas e instituições culturais em diversos países, como o Rijksmuseum, nos Países Baixos, e a Digital Public Library of America (DPLA), nos Estados Unidos. Por meio dessa plataforma, as instituições do patrimônio cultural parceiras podem configurar e executar campanhas para envolver desde especialistas em cultura, estudantes, pesquisadores, até o público em geral (CrowdHeritage Platform, 2020; Crowdheritage, 2021).
Projetada para levar em consideração as particularidades e os requisitos estabelecidos pelo domínio do patrimônio cultural, a CrowdHeritage dispõe de vários recursos de customização que a tornam aplicável em uma grande variedade de casos de uso e tipos de coleções, oferecendo funcionalidades administrativas para que os organizadores da campanha possam acompanhar, customizar e moderar os resultados das anotações feitas pelos usuários. Esses resultados, por sua vez, podem ser integrados aos fluxos de trabalho das instituições e iniciativas de agregação por meio do mapeamento para padrões comuns que convertem as anotações em dados semanticamente estruturados via APIs compatíveis com as soluções da Web Semântica.
Além disso, há a possibilidade de combinar os serviços de crowdsourcing às ferramentas de enriquecimento automático baseadas em inteligência artificial e aprendizado de máquina que criam anotações a partir das características extraídas de recursos informacionais. A partir disso, um conjunto de dados enriquecidos automaticamente com anotações pode ser colocado para validação via voto na plataforma. Ao mesmo tempo, os conjuntos de dados anotados por humanos durante as campanhas podem ser usados como dados verdadeiros para processos de treinamento e ajustes de algoritmos no enriquecimento automático (Kaldeli et al., 2021). Assim, contribuindo reciprocamente, as tarefas de anotação humana são orientadas e facilitadas pela anotação automática, enquanto as anotações automáticas têm seu desempenho e precisão melhorados pelo julgamento humano, especialmente em relação às características específicas de domínio.
Dessa forma, os metadados contribuídos podem ser usados diretamente para melhorar os serviços de pesquisa nas plataformas de apresentação das coleções, suportando um rico conjunto de representações provenientes da ação conjunta entre humano-máquina. Ainda, no que se refere ao controle terminológico, o processo de enriquecimento é validado por profissionais e especialistas em função do domínio do conhecimento visando garantir o máximo de aproveitamento para melhorar tarefas, como curadoria, descoberta e criação de coleções.
Em termos funcionais, a plataforma CrowdHeritage apresenta-se em uma infraestrutura de três componentes internos básicos: a) o sistema de agregação e gerenciamento de coleção; b) o ambiente de crowdsourcing da Web destinado ao usuário; c) as interfaces administrativas para design, personalização e processo de moderação e validação das campanhas. Essa infraestrutura, chamada de backend (estrutura interna), é construída em cima da plataforma WITHCulture,5 na qual o sistema de agregação opera fornecendo acesso a itens de diferentes repositórios a partir de serviços de pesquisa federada e facetada. Esses serviços oportunizam a busca simultânea em vários repositórios, dando acesso a um conjunto de itens heterogêneos que incluem imagens, vídeos, juntamente com os esquemas de metadados que são convertidos em um modelo homogêneo de dados compatível com o modelo de dados Europeana (EDM) (Kaldeli et al., 2021).
Uma funcionalidade importante que foi alcançada pela CrowdHeritage é o suporte ao multilinguismo de forma dinâmica, tanto no que diz respeito à interface da plataforma que está disponível atualmente em inglês, italiano e francês, quanto no suporte ao processo de anotação, a partir da etiquetagem, com vocabulários e tesauros multilíngues que auxiliam na escolha dos descritores a partir das funcionalidades de autocompletar. Além disso, o ambiente de crowdsourcing da Web destinado ao usuário suporta diferentes formas de anotação semântica de registros com termos de vocabulários controlados e tesauros, marcação de cores e itens de geotagging (Kaldeli et al., 2021), o que garante uma assistência sobre as atividades colaborativas.
Dessa forma, entre os benefícios da plataforma, destaca-se o fato de que as campanhas personalizadas incentivam as pessoas a se envolverem com o patrimônio cultural, usando uma abordagem intuitiva e elementos de gamificação que melhoram a experiência do usuário, a qualidade e a capacidade de descoberta de material para sua reutilização mais ampla e a conscientização sobre coleções on-line, inclusive entre pessoas que não falam inglês, uma vez que há a possibilidade de contribuir com anotações em diversas línguas (CrowdHeritage Platform, 2020).
Logo, qualquer pessoa interessada pode adicionar termos aos registros de metadados dos objetos culturais selecionados para uma campanha ou validar os existentes de modo simplificado e interativo envolvendo ativamente o público com o material do patrimônio cultural, como, por exemplo, por meio de placares ou recompensas (Crowdheritage, 2021). A figura 2 apresenta uma das campanhas ativas na página da plataforma.

Na figura 2 é possível ver um exemplo de contribuição a um item de uma coleção. A imagem diz respeito a uma peça decorativa do Parque Güell, na Espanha criada pelo artista e arquiteto Antoni Gaudí, acompanhada de suas informações e ao lado um espaço para contribuir, neste caso, via voto positivo ou negativo em características previamente específicas acerca desse item.
Essa estratégia permite criar além dos atrativos visuais nos quais os usuários são estimulados pela interface a interagirem com os elementos de gamificação, sobretudo gerando engajamento devido à oportunidade de participar de posicionamentos culturais, nos quais os usuários são “consultados” acerca de uma determinada narrativa cultural representada por meio das coleções digitais.
5.2 Arquigrafia
O projeto que deu origem à plataforma Arquigrafia configura-se como uma iniciativa de conservação, digitalização e difusão na Web de material fotográfico original do Setor de Materiais Iconográficos da Biblioteca da FAU/USP, realizado entre 2010 e 2017. Como resultado do projeto, desenvolveu-se um ambiente colaborativo aberto, público e sem fins lucrativos, dedicado ao compartilhamento de imagens fotográficas da arquitetura e urbanismo brasileiro (Rozestraten, Andrade & Figueiredo, 2018).
Seu conteúdo é principalmente formado pelo conjunto de imagens que foram digitalizadas do acervo FAU/USP e o restante é composto pelo material que é enviado de forma contributiva ao sistema juntamente com as autorizações de licença Creative Commons. Como uma plataforma Web, a Arquigrafia envolve uma rede heterogênea de colaboradores, que inclui utilizadores institucionais, ONGs, Universidades, grupos de pesquisa e demais utilizadores como alunos, professores, fotógrafos e pessoas em geral. Esses colaboradores, mais do que enviar objetos iconográficos, podem compartilhar avaliações, impressões e julgamentos sobre as características arquitetônicas representadas nas fotografias (Lima, Santos & Rozestraten, 2020).
Desse modo, a proposta da Arquigrafia está fundamentada na ideia de ampliar os níveis de envolvimento da comunidade interessada para aprimorar a experiência do público com as coleções. Para isso, a equipe buscou desenvolver frentes tecnológicas de modo a suportar a criação de um modelo colaborativo de representação da informação, no qual os usuários são convidados a participar do processo de atribuição de termos temáticos e contextuais para as coleções. As funcionalidades da plataforma incluem a possibilidade de que, ao contribuírem com um conteúdo, os usuários possam representá-lo, tanto usando uma lista de sugestões derivada do Vocabulário Controlado do Sistema Integrado de Bibliotecas da Universidade de São Paulo (VOCAUSP),6 como adicionando termos próprios. Além disso, outros usuários podem revisar as informações de representação já atribuídas e indicar acréscimos ou correções por meio do sistema (Santos, Lima & Rozestraten, 2018).
A partir disso, a ideia do projeto foi ampliar o nível de colaboração de modo a formar um “sistema de organização do conhecimento misto” (Lima, Santos & Rozestraten, 2020, p. 59, tradução nossa), isto é, criar um vocabulário que integre os termos de representação, incluindo as listas de assuntos utilizadas pela instituição para a indexação das imagens e os termos de arquitetura e urbanismo do VOCAUSP, bem como a lista de tags padrão gerada no âmbito do sistema da Arquigrafia com base nos termos atribuídos pelos usuários.
Em 2018, a equipe responsável pelo projeto lançou a segunda edição do Manual de Procedimentos Técnicos do Projeto Arquigrafia (Rozestraten, Andrade & Figueiredo, 2018), no qual explicam que a lista de tags está em elaboração com base em um constante levantamento de dados, pois, na medida em que a contribuição de termos é constante, o gerenciamento do vocabulário da Arquigrafia precisa ocorrer continuamente. Desse modo, de acordo com o manual, a primeira lista de termos para indexação do Arquigrafia foi elaborada pela equipe na implantação do projeto, sendo os termos organizados em quatro grandes categorias: materiais (referente à composição material); elementos arquitetônicos (referente às características arquitetônicas); tipologia (referente à forma da edificação); e função (referente ao uso da edificação).
Após um período de funcionamento, entre os anos de 2017 e 2019, os termos da lista de tags atribuídas por usuários foram submetidos ao processo de padronização para inclusão no vocabulário controlado. Atualmente, os termos são incluídos em cinco categorias constituindo o primeiro nível da estrutura do vocabulário controlado. São elas: forma (tipo de construção); função (uso do edifício, passado ou presente); materiais (materiais usados na construção); técnica (técnica de construção utilizada); e história. Para isso, um trabalho de identificação dos termos foi realizado pela equipe de alunos e professores, buscando estabelecer as relações lógicas e ontológicas com base na definição, fonte, referências e sinônimos, hierarquia e categoria institucionais; e consistência com as imagens indexadas (Lima, Santos & Rozestraten, 2020).
Recentemente, a plataforma apresentou o projeto piloto “ARQUIGRAFIA: Open-Air Museum (Museu a Céu Aberto)”, proveniente da convergência experimental entre o projeto Arquigrafia e o Smart Audio City Guide,7 ambos desenvolvidos por equipes multidisciplinares de pesquisadores da Universidade de São Paulo (USP). A intenção do projeto é viabilizar e ampliar a interação dos usuários com as paisagens, os espaços e objetos urbanos a partir de suas representações – imagens, textos e áudios – que, por sua vez, podem ser enriquecidas pelas impressões e experiências sensoriais diretas dos usuários com os ambientes físicos, estimulando ressignificações, reposicionamentos e revisões contínuas dos conhecimentos construídos a respeito dos elementos da cidade, suas dinâmicas e transformações (Rozestraten, Bertholdo, Faria & Silva, 2017). Assim, os usuários são convidados a contribuir com áudios e textos descritivos, bem como novos ângulos em registros fotográficos dos espaços físicos.
Com relação às funcionalidades da plataforma, a partir de um perfil, os usuários têm acesso a um conjunto de interfaces, como seção para bate-papo, inserção de conteúdo, criação de coleções personalizadas com curadoria de conteúdo, possibilidade de seguir coleções e interface de contribuição que inclui elementos de gamificação para estimular os usuários a revisar a representação das imagens e a fazer comentários e sugestões. Essas funcionalidades podem ser acessadas com a criação de uma conta no endereço eletrônico da Arquigrafia.8 Para contribuir, os usuários podem realizar revisões e edições que são analisadas, aceitas ou recusadas pela equipe moderadora na interface “Contribuições”. Isso inclui sugerir ou corrigir tags de geolocalização e registrar impressões e interpretações acerca da imagem. Ainda, os registros dos itens da coleção que foram criados a partir do Acervo da Biblioteca da FAUUSP ou definidos por membros do Arquigrafia podem ser aprimorados com informações adicionais enviando e-mails.
A funcionalidade mais visual oferecida pela plataforma é a possibilidade de formular julgamentos sobre edifícios e espaços urbanos representados nas fotografias a partir de pares de qualidades plástico-espaciais opostas, denominadas binômios. Lima, Santos e Rozestraten (2020, p. 57, tradução nossa) explicam que:
Os binômios são organizados como diferenciais semânticos, tais como: aberto / fechado; interno externo; translúcido / opaco; complexo / simples; simétrico / assimétrico; horizontal vertical. Os fundamentos conceituais para esses pares de qualidades opostas vêm de Henrich Wölfflin (1864-1945) "Princípios de História da Arte" (1950), adaptado para Arquitetura, organizado como diferenciais semânticos de Charles E. Osgood (1916-1991) (1990).
No momento do registro de suas impressões sobre uma imagem, os usuários podem escolher entre seis pares de qualidades opostas. A figura 3 permite visualizar um exemplo dessa contribuição na plataforma Arquigrafia.
Figura 3 Contribuição a partir do registro de impressões sobre uma imagem.

Fonte: Arquigrafia (2022).
Na figura 3 é possível ver a imagem do Parque da Independência, localizado no bairro do Ipiranga em São Paulo, SP - Brasil, acompanhada de tags representativas abaixo e, ao lado, de uma área dedicada à interação do usuário, que pode escolher para cada um dos pares de características, a que mais se adequa ao que está sendo visualizado.
Esses dados são coletados e usados para gerar uma média para cada imagem com a qual o sistema pode comparar recursos imagéticos e criar padrões de semelhança para a identificação e recuperação, possibilitando ainda orientar as navegações nos sistemas por meio de interações entre imagens com características semelhantes (Lima, Santos & Rozestraten, 2020).
Outra funcionalidade que ainda auxilia na redução dos custos de desenvolvimento é a possibilidade de utilizar APIs de outros sistemas de modo a promover a integração. A localização de cada imagem está integrada à API do Google Maps (Rozestraten, Martinez, Gerosa, Kon & Santos 2010), o que permite exibir um mapa do local referente à imagem.
Desse modo, a plataforma Arquigrafia está em constante aprimoramento dos seus serviços oferecendo aos usuários um ambiente interativo que contribui para o estudo e a difusão do conteúdo cultural referente à área de Arquitetura e afins, promovendo o diálogo e construindo um conjunto de informações e conhecimentos dinâmicos e reutilizáveis.
5.3 Categorias comparativas
Após a aplicação metodológica foram identificadas nove categorias de análise pertinentes à proposta. Essas categorias, apresentadas no Quadro 2, foram identificadas e nomeadas de acordo com a observação dos aspectos e funcionalidades presentes nas interfaces das plataformas dos projetos, bem como em seus documentos primários e publicações científicas que orientaram o trabalho de sistematização das relações existentes entre os fundamentos encontrados.
A primeira categoria, (1) Domínio de aplicação, refere-se ao escopo em que cada plataforma atua. A segunda categoria, (2) Formas de contribuição, refere-se a maneira pela qual os usuários podem participar das ações de colaboração disponibilizadas pelas plataformas. A terceira categoria, (3) Tipos de representação, diz respeito aos tipos de representação com que os usuários podem contribuir em cada plataforma, são elas: descritiva (evidenciando as características físicas dos objetivos informacionais representados) e/ou temática (representando o(s) assuntos dos objetos informacionais).
A categoria (4) Sugestão de termos e recursos de padronização, faz referência à forma com que os usuários fazem a sugestão dos termos no processo colaborativo de representação e como cada plataforma presta assistência aos seus usuários para que contribuam com o conteúdo de modo padronizado.
A quinta categoria, (5) Revisão da contribuição, diz respeito ao processo de moderação que cada modelo colaborativo de representação adota na plataforma mediante a inclusão de perfis como "superadministrador" ou "admnistrador" com o objetivo de analisar as contribuições apresentadas pelos usuários a partir de recursos colaborativos como a etiquetagem, por exemplo. A próxima categoria, (6) Inclusão de recursos informacionais, faz referência às maneiras pelas quais os usuários podem incluir novos recursos informacionais na plataforma, ampliando a coleção. Quanto à categoria (7) Engajamento dos usuários, esta reflete a forma com que cada uma das plataformas incentiva sua comunidade interessada a acessar ao conteúdo e contribuir, corrigindo e fornecendo mais informações.
A penúltima categoria, (8) Recursos de busca e recuperação, demostra como cada plataforma dispõe seu conteúdo para o aproveitamento da colaboração, da busca e da recuperação dos recursos informacionais disponíveis nesses ambientes. A décima e última categoria definida trata-se dos (9) Trabalhos futuros, a qual descreve quais têm sido os direcionamentos que as plataformas pretendem dar aos seus serviços de modo a aprimorar a colaboração.



Frente às análises apresentadas, fica claro que ambas as propostas buscam estabelecer suas funcionalidades com base nos preceitos da Web, tirando proveito das soluções de interoperabilidade e sustentabilidade dos ambientes colaborativos em rede.
Nas duas propostas, verifica-se a preocupação em moderar o sistema colaborativo, ou seja, há a intervenção de um usuário administrador ou organizador que vai validar as escolhas dos usuários, seja na livre digitação ou usando a sugestão do sistema. Há também a preocupação em apresentar as sugestões com base na relação entre os termos do domínio selecionado a partir de uma estrutura de representação de conhecimento prévia.
Em ambos os casos também os termos escolhidos pelos usuários na forma de tags são aproveitados, não só para a recuperação da informação, mas também para processos de apresentação, o que inclui formação de coleções e co-curadoria. Contudo, em ambas as plataformas verifica-se a ausência de elementos que poderiam contribuir na interface de busca e recuperação do conteúdo. Tanto na interface da Arquigrafia, quanto da Europeana (maior utilizador das campanhas na CrowdHeritage) não é encontrado nuvens de tags, uma ferramenta de navegação importante dada às características colaborativas de ambos os ambientes analisados.
Por outro lado, as plataformas diferem em relação à forma de aproveitamento dessa inteligência coletiva dos colaboradores, visto que possuem diferenças de escopo e de abrangência: enquanto uma contempla uma grande variedade de coleções e destina-se a enriquecer várias bases de dados (CrowdHeritage), a outra dedica-se a um setor temático específico enriquecendo somente sua própria base (Arquigrafia).
A CrowdHeritage, até mesmo por sua amplitude, apoia-se massivamente nos processos automatizados que usam a inteligência artificial para extrair características das imagens, com vistas a otimizar o processo de representação. Logo, verifica-se que a colaboração dos usuários está mais voltada ao processo de validar essas características extraídas automaticamente das imagens. Contudo, por propor um serviço flexível de crowdsoursing, cada campanha, mobilizada por uma instituição ou iniciativa agregadora, pode escolher a melhor forma de aproveitar o julgamento e a participação colaborativa dos seus usuários, o que inclui as diversas formas de anotação semântica que posteriormente são acomodadas às estruturas de representação do conhecimento apoiadas nas tecnologias da Web, podendo caracterizar um sistema híbrido de Organização do Conhecimento. Outra característica consolidada na CrowdHeritage é a reutilização de diversos vocabulários Linked Data para ampliar a base de conhecimento acerca de um objeto cultural, bem como seu espectro linguístico.
Já na Arquigrafia, a colaboração dos usuários é aproveitada de forma mais simples e direta pelo sistema, cuja estrutura de representação do conhecimento é atualizada para acomodar os novos termos a um único vocabulário colaborativo. Assim, esse vocabulário inclui, além de termos provenientes da indexação institucional, tags oriundas da indexação social, ficando a cargo da equipe validar as relações entre os descritores. A validação e padronização terminológica têm sido feita de forma manual, a partir de procedimentos terminológicos e de construção de vocabulários controlados indicados na norma ISO 25964-1/2011.9
De tal modo, diferente da CrowdHeritage, percebe-se que a plataforma Arquigrafia ainda está desenvolvendo suas funcionalidades em vista de um ambiente propriamente de crowdsourcing, com sistema de moderação integrado e elementos de gamificação. Contudo, seu desenvolvimento atual com Design Centrado no Usuário (UCD) já demonstra um sólido modelo de colaboração, principalmente no que diz respeito à construção de um sistema híbrido de organização do conhecimento.
Considerações finais
O processo de enriquecimento semântico com base na contribuição da comunidade interessada tem se tornando uma iniciativa bastante comum entre as instituições culturais que buscam as potencialidades da Web para ampliar seus espaços de atuação. Dois exemplos diferentes de propostas de modelos colaborativos do patrimônio cultural foram apresentados e discutidos neste trabalho.
O primeiro é o caso da plataforma CrowdHeritage, desenvolvida para apoiar e enriquecer coleções heterogêneas de grandes iniciativas de agregação de dados do patrimônio cultural, como Europeana e Digital Public Library of America (DPLA),10 configurando-se como uma robusta iniciativa de crowdsourcing que oferece diferentes funcionalidades para aproveitar a inteligência coletiva dos colaboradores. O outro caso analisado é o da Arquigrafia, desenvolvida em âmbito brasileiro na FAU/USP em um ambiente dotado de frentes tecnológicas colaborativas que está buscando ampliar constantemente seu nível de colaboração.
Visto as semelhanças e diferenças, em ambos os casos foi identificada a implementação de modelos colaborativos de representação da informação que fazem uso das possibilidades da folksonomia, sem, no entanto, deixar de considerar os desafios que ela traz. Fica evidente, portanto, que a comparação desenvolvida não se destina a equiparar os objetos e os serviços ofertados em cada projeto, visto que possuem escopos e amplitudes diferentes, mas sim lançar um olhar sobre as possibilidades e sobre os elementos constituintes de seus sistemas colaborativos que fazem uso do crowdsourcing, que de formas diferentes apresentam importantes contribuições à melhoria da qualidade de metadados do patrimônio cultural.
No caso da CrowdHeritage, observa-se que apesar de oferecer uma grande base de sugestões, com vários vocabulários temáticos em Linked Data para os usuários, o nível de contribuição é restringido aos objetivos da campanha de crowdsourcing por seus editores, que em geral adotam o formato de votação de tags pré-determinadas ou buscam direcionar as escolhas pela função de autocompletar, caracterizando um processo de folksonomia assistida. Comparado com a Arquigrafia, a liberdade de escolha das tags na plataforma brasileira é maior, pois um conjunto de etiquetas pode ser inserido pelo usuário a cada nova imagem enviada ao sistema. Assim, nesse último caso, há a coexistência da folksonomia e dos vocabulários controlados institucionais para a retroalimentação e representação da informação, caracterizando um sistema híbrido de organização do conhecimento.
Vale destacar que essa aparente ausência de liberdade no processo de indexação social ocasionada pela assistência dada aos usuários não é algo desfavorável, ao contrário, evita inconsistências na posterior recuperação da informação e não engessa a criatividade e participação desses sujeitos no ambiente, contribuindo assim para a garantia cultural no domínio do patrimônio cultural.
Porém, o que os estudos da fundamentação teórica indicam e este trabalho tentou contribuir é que deve ser um processo balanceado e previamente planejado, no qual o universo semântico e contextual dos usuários pode potencializar as estruturas formalizadas em padrões.

